🍒 Emote
Emote — E\ mbark's Mo\ dular T\ raining E\ ngine — is a flexible framework for reinforcement learning written at Embark.
Installation
For package managemend and environment handling we use pants. Install it from pants. After pants is set up, verify that it is setup by running
pants tailor ::
Ideas and Philosophy
We wanted a reinforcement learning framework that was modular both in the sense that we could easily swap the algorithm we used and how data was collected but also in the sense that the different parts of various algorithms could be reused to build other algorithms.
📄 Coding standard
In emote we strive to maintain a consistent style, both visually and implementation-wise. In order to achieve this we rely on tools to check and validate our code as we work, and we require that all those tools are used for CI to pass.
To have a smooth developer experience, we suggest you integrate these with your editor. We'll provide some example configurations below; and we welcome contributions to these pages. However, we strive to avoid committing editor configurations to the repository, as that'll more easily lead to mismatch between different editors - the description below is authoritative, not any specific editor configuration.
We also require that all commits are made using LF-only line endings. Windows users will need to configure using the below command, or set up their editor appropriately. This helps keep emote platform-generic, and reduces risk for spurious diffs or tools misbehaving.
git config --global core.autocrlf true
Tools
To run the tools mentioned below on the whole repo, the easiest way is with
pants lint ::
black
Black is an auto-formatter for Python,
which mostly matches the PEP8 rules. We use black because it doesn't
support a lot of configuration, and will format for you - instead of
just complaining. We do allow overrides to these styles, nor do we
allow disabling of formatting anywhere.
isort
isort is another formatting tool,
but deals only with sorting imports. Isort is configured to be
consistent with Black from within pyproject.toml.
Example configurations
emacs
(use-package python-black
:demand t
:after python
:hook (python-mode . python-black-on-save-mode-enable-dwim))
(use-package python-isort
:demand t
:after python
:hook (python-mode . python-isort-on-save-mode))
📚 Documentation
To write documentation for emote we use mdBook written in Markdown (.md) files. These can reference each other, and will be built into a book like HTML bundle.
See the mdBook markdown docs for details about syntax and feature support.
Helpful commands
- To build the docs:
pants package //docs:book - To view the docs in your browser:
pants run //docs:serveand then visit http://localhost:8000
🌡 Metrics
Emote can log metrics from two locations: inside the training loop, and outside the training
loop. The base for this is the LoggingMixin class in both cases,
adds logging functionality to anything. However, it doesn't do any actual logging.
On the training side, the second part of the puzzle is a LogWriter, for example
TensorboardLogger. We also provide a built-in
TerminalLogger. These accept a list of objects derived from
LoggingMixin, and will execute the actual writing of values from
the previously of values. This makes implementing log-data-providers easier, as they do not have to
care about when to write, only how often they can record data.
logger = SystemLogger()
tensorboard_log_writer = TensorboardLogger([logger], SummaryWriter("/tmp/output_dir"), 2000)
trainer = Trainer([logger, tensorboard_log_writer])
Things behave slightly differently on the data-generation side. Our suggested (and only supported
method) is to wrap the memory with a LoggingProxyWrapper. Since all data going into the training loop passes through the memory, and all data has associated metadata, this will capture most metrics.
Our suggestion is that users primarily rely on this mechanism for logging data associated with the agents, as it will get smoothed across all agents to reduce noise.
env = DictGymWrapper(AsyncVectorEnv(10 * [HitTheMiddle]))
table = DictObsMemoryTable(spaces=env.dict_space, maxlen=1000, device="cpu")
table_proxy = MemoryTableProxy(table, 0, True)
table_proxy = LoggingProxyWrapper(table, SummaryWriter("/tmp/output_dir"), 2000)
🔥 Getting Started
In the /experiments folder, example runs can be found for different Gymnasium environments.
For example, you can run the cartpole example using DQN with the following command:
pants run //experiments/gym/train_dqn_cartpole.py@resolve=base

This comes with a lot of predefined arguments, such as the learning rate, the amount of hidden layers, the batch size, etc. You can find all the arguments in the experiments/gym/train_dqn_cartpole.py file.
📊 Tensorboard
To visualize the training process, you can use Tensorboard. To do so, run the following command:
pants run //:tensorboard -- --logdir ./mllogs
This will start a Tensorboard server on localhost:6006. You can now open your browser and go to http://localhost:6006 to see the training process where you can see the rewards over time, the loss over time, etc.

Callback system
In this module you'll find the callback framework used by Emote. Those who have used FastAI before will recognize it, as it's heavily inspired by that system - but adapted for RL and our use-cases.
The Callback interface
The callback is the core interface used to hook into the Emote framework. You can think of these as events - when the training loop starts, we'll invoke begin_training on all callback objects. Then we'll start a new cycle, and call :meth:Callback.begin_cycle for those that need it.
All in all, the flow of callbacks is like this:
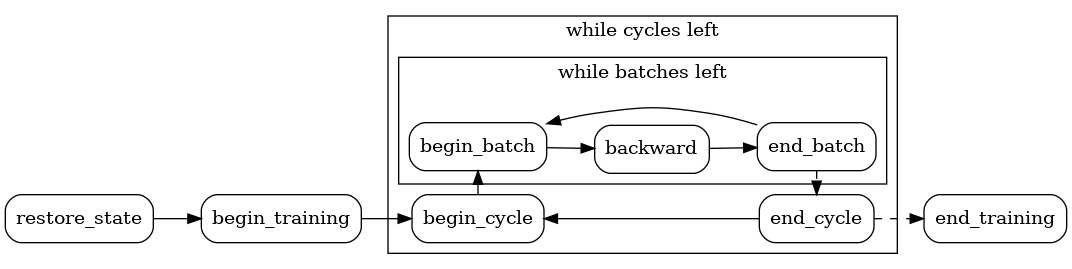
package emote
Emote
In order to do reinforcement learning we need to have two things: A learning protocol that specifies which losses to use, which network architectures, which optimizers, and so forth. We also need some kind of data collector that interacts with the world and stores the experiences from that in a way which makes them accessible to the learning protocol.
In Emote, data collection is done by Collectors, the protocol for the learning algorithm is built up of Callbacks, and they are tied together by a Trainer.
Classes
class Callback:
The principal modular building block of emote. Callbacks are modular pieces of code that together build up the training loop. They contain hooks that are executed at different points during training. These can consume values from other callbacks, and generate their own for others to consume. This allows a very loosely coupled flow of data between different parts of the code. The most important examples of callbacks in emote are the Losses.
The concept has been borrowed from Keras and FastAI.
Methods
def __init__(self, cycle) -> None
Arguments:
cycle(int | None)
def restore_state(self) -> None
Called before training starts to allow loader modules to import state.
At this point, no assumptions can be made for other modules state.
def begin_training(self) -> None
Called when training starts, both from scratch and when restoring from a checkpoint.
def begin_cycle(self) -> None
Called at the start of each cycle.
def begin_batch(self) -> None
Called at the start of each batch, immediately after data has been sampled.
def backward(self) -> None
The main batch processing should happen here.
def end_batch(self) -> None
Called when the backward pass has been completed.
def end_cycle(self) -> None
Called when a callbacks cycle is completed.
def end_training(self) -> None
Called right before shutdown, if possible.
def state_dict(self) -> Dict[str, Any]
Called by checkpointers primarily to capture state for on-disk saving.
def load_state_dict(
self,
state_dict,
load_network,
load_optimizer,
load_hparams
) -> None
Called from checkpoint-loaders during the restore_state phase,
primarily.
Arguments:
state_dict(Dict[str, Any])load_network(bool)(default: True)load_optimizer(bool)(default: True)load_hparams(bool)(default: True)
class Trainer:
The Trainer class manages the main training loop in emote. It does so by invoking a bunch of callbacks in a number of different places.
Fields
-
state:StateDict -
callbacks:List[Callback] -
dataloader:Iterable -
cycle_length:int
Methods
def __init__(self, callbacks, dataloader, batch_size_key) -> None
Arguments:
callbacks(List[Callback])dataloader(Iterable)batch_size_key(str)(default: batch_size)
def train(self, shutdown_signal) -> None
The main training loop. This method will wait until the memory is full enough to start sampling, and then start running cycles of backprops on batches sampled from the memory.
Arguments:
shutdown_signal(Callable): A function that returns True if training shut end, False otherwise.
package emote.algorithms
module emote.algorithms.action_symmetry
Classes
class ActionSymmetryDiscriminatorLoss(LossCallback):
This loss is used to train a discriminator for adversarial training.
Methods
def __init__(
self,
discriminator,
right_action_map_fn,
left_action_map_fn,
grad_loss_weight,
optimizer,
lr_schedule,
max_grad_norm,
data_group,
name
) -> None
Arguments:
discriminator(Discriminator)right_action_map_fn(Callable[[Tensor], Tensor])left_action_map_fn(Callable[[Tensor], Tensor])grad_loss_weight(float)optimizer(torch.optim.Optimizer)lr_schedule(torch.optim.lr_scheduler._LRScheduler)max_grad_norm(float)data_group(str)name(str)
def loss(self, actions) -> Tensor
Computing the loss to train a discriminator to classify right-side from left-side action values.
Arguments:
actions
class ActionSymmetryAMPReward(LoggingMixin, Callback):
Adversarial rewarding with AMP.
Methods
def __init__(
self,
discriminator,
right_action_map_fn,
left_action_map_fn,
confusion_reward_weight,
data_group
) -> None
Arguments:
discriminator(Discriminator)right_action_map_fn(Callable[[Tensor], Tensor])left_action_map_fn(Callable[[Tensor], Tensor])confusion_reward_weight(float)data_group(str)
def begin_batch(self, actions, rewards) -> None
Updating the reward by adding the weighted AMP reward
Arguments:
actions(Tensor): batch of actionsrewards(Tensor): task reward
module emote.algorithms.amp
Functions
def gradient_loss_function(model_output, model_input) -> Tensor
Given inputs and outputs of an nn.Module, computes the sum of squared derivatives of outputs to the inputs Arguments: model_output (Tensor): the output of the nn.Module model_input (Tensor): the input to the nn.Module Returns: loss (Tensor): the sum of squared derivatives
Arguments:
model_output(Tensor)model_input(Tensor)
Classes
class DiscriminatorLoss(LossCallback):
This loss is used to train a discriminator for adversarial training.
Methods
def __init__(
self,
discriminator,
imitation_state_map_fn,
policy_state_map_fn,
grad_loss_weight,
optimizer,
lr_schedule,
max_grad_norm,
input_key,
name
) -> None
Arguments:
discriminator(nn.Module)imitation_state_map_fn(Callable[[Tensor], Tensor])policy_state_map_fn(Callable[[Tensor], Tensor])grad_loss_weight(float)optimizer(torch.optim.Optimizer)lr_schedule(torch.optim.lr_scheduler._LRScheduler)max_grad_norm(float)input_key(str)(default: features)name(str)(default: Discriminator)
def loss(self, imitation_batch, policy_batch) -> Tensor
Computing the loss
Arguments:
imitation_batch(dict): a batch of data from the reference animation. the discriminator is trained to classify data from this batch as positive samplespolicy_batch(dict): a batch of data from the RL buffer. the discriminator is trained to classify data from this batch as negative samples.
Returns:
- loss (Tensor): the loss tensor
class AMPReward(LoggingMixin, Callback):
Adversarial rewarding with AMP.
Methods
def __init__(
self,
discriminator,
state_map_fn,
style_reward_weight,
rollout_length,
observation_key,
data_group
) -> None
Arguments:
discriminator(nn.Module)state_map_fn(Callable[[Tensor], Tensor])style_reward_weight(float)rollout_length(int)observation_key(str)data_group(str)
def begin_batch(self, observation, next_observation, rewards) -> None
Updating the reward by adding the weighted AMP reward
Arguments:
observation(dict[str, Tensor]): current observationnext_observation(dict[str, Tensor]): next observationrewards(Tensor): task reward
module emote.algorithms.dqn
Classes
class QTarget(LoggingMixin, Callback):
Methods
def __init__(
self
,
*q_net,
target_q_net,
gamma,
reward_scale,
target_q_tau,
data_group,
roll_length
) -> None
Compute and manage the target Q-values for Q-Learning algorithms.
Arguments:
q_net(nn.Module): The Q-network.target_q_net(Optional[nn.Module]): The target Q-network. Defaults to a copy of q_net. (default: a copy of q_net)gamma(float): Discount factor for future rewards.reward_scale(float): A scaling factor for the reward values.target_q_tau(float): A soft update rate for target Q-network.data_group(str): The data group to store the computed Q-target.roll_length(int): The rollout length for a batch.
def begin_batch(self, next_observation, rewards, masks) -> None
def end_batch(self) -> None
class QLoss(LossCallback):
Compute the Q-Learning loss.
Methods
def __init__(
self
,
*name,
q,
opt,
lr_schedule,
max_grad_norm,
data_group,
log_per_param_weights,
log_per_param_grads
) -> None
Arguments:
name(str): Identifier for this loss component.q(nn.Module): The Q-network.opt(optim.Optimizer): The optimizer to use for the Q-network.lr_schedule(Optional[optim.lr_scheduler._LRScheduler]): Learning rate scheduler.max_grad_norm(float): Maximum gradient norm for gradient clipping.data_group(str): The data group from which to pull data.log_per_param_weights(bool): Whether to log weights per parameter.log_per_param_grads(bool): Whether to log gradients per parameter.
def loss(self, observation, q_target, actions) -> None
package emote.algorithms.genrl
module emote.algorithms.genrl.proxies
Classes
class MemoryProxyWithEncoder(MemoryTableProxy):
Methods
def __init__(
self,
memory_table,
encoder,
minimum_length_threshold,
use_terminal,
input_key,
action_key
) -> None
def add(self, observations, responses) -> None
module emote.algorithms.genrl.vae
Classes
class VariationalAutoencoder(nn.Module):
Methods
def __init__(self, encoder, decoder, device, beta) -> None
def forward(self, x, condition) -> None
def loss(self, x, x_hat, mu, log_std) -> None
class VAELoss(LossCallback):
Methods
def __init__(
self
,
*vae,
opt,
lr_schedule,
max_grad_norm,
name,
data_group,
input_key,
conditioning_func
) -> None
def loss(self, observation, actions) -> None
module emote.algorithms.genrl.wrappers
Classes
class DecoderWrapper(nn.Module):
Methods
def __init__(self, decoder, condition_fn, latent_multiplier) -> None
def forward(self, latent, observation) -> torch.Tensor
Running decoder.
Arguments:
latent(torch.Tensor): batch x latent_sizeobservation(torch.Tensor): batch x obs_size
Returns:
- the sample (batch x data_size)
def load_state_dict(self, state_dict, strict) -> None
class EncoderWrapper(nn.Module):
Methods
def __init__(self, encoder, condition_fn) -> None
def forward(self, action, observation) -> torch.Tensor
Running encoder.
Arguments:
action(torch.Tensor): batch x data_sizeobservation(torch.Tensor): batch x obs_size
Returns:
- the mean (batch x data_size)
def load_state_dict(self, state_dict, strict) -> None
class PolicyWrapper(nn.Module):
module emote.algorithms.hlgauss
Classes
class LogitNet(nn.Module):
The QNet assumes that the input network has a num_bins property.
Methods
def __init__(self, num_bins) -> None
Arguments:
num_bins
class QNet(nn.Module):
The HL Gauss QNet needs to output both the q-value based on the input and to convert logits to q.
Methods
def __init__(self, logit_net, min_value, max_value) -> None
Arguments:
logit_net(LogitNet)min_value(float)max_value(float)
def forward(self) -> Tensor
def q_from_logit(self, logits) -> Tensor
class HLGaussLoss(nn.Module):
A HLGauss loss as described by Imani and White. Code from Google Deepmind's https://arxiv.org/pdf/2403.03950v1.pdf.
Methods
def __init__(self, min_value, max_value, num_bins, sigma) -> None
Arguments:
min_value(float): Minimal value of the range of target bins.max_value(float): Maximal value of the range of target bins.num_bins(int): Number of bins.sigma(float): Standard deviation of the Gaussian used to convert regression targets to distributions.
def forward(self, logits, target) -> torch.Tensor
def transform_to_probs(self, target) -> torch.Tensor
class QLoss(LossCallback):
A classification loss between the action value net and the target q. The target q values are not calculated here and need to be added to the state before the loss of this module runs.
Methods
def __init__(
self
,
*name,
q,
opt,
lr_schedule,
max_grad_norm,
smoothing_ratio,
data_group,
log_per_param_weights,
log_per_param_grads
) -> None
Arguments:
name(str): The name of the module. Used e.g. while logging.q(QNet): A deep neural net that outputs the discounted loss given the current observations and a given action.opt(optim.Optimizer): An optimizer for q.lr_schedule(Optional[optim.lr_scheduler._LRScheduler]): Learning rate schedule for the optimizer of q.max_grad_norm(float): Clip the norm of the gradient during backprop using this value.smoothing_ratio(float): The HL Gauss smoothing ratio is the standard deviation of the Gaussian divided by the bin size.data_group(str): The name of the data group from which this Loss takes its data.log_per_param_weights((bool)): If true, log each individual policy parameter that is optimized (norm and value histogram).log_per_param_grads((bool)): If true, log the gradients of each individual policy parameter that is optimized (norm and histogram).
def loss(self, observation, actions, q_target) -> None
module emote.algorithms.sac
Functions
def soft_update_from_to(source, target, tau) -> None
Classes
class QLoss(LossCallback):
A MSE loss between the action value net and the target q. The target q values are not calculated here and need to be added to the state before the loss of this module runs.
Methods
def __init__(
self
,
*name,
q,
opt,
lr_schedule,
max_grad_norm,
data_group,
log_per_param_weights,
log_per_param_grads
) -> None
Arguments:
name(str): The name of the module. Used e.g. while logging.q(nn.Module): A deep neural net that outputs the discounted loss given the current observations and a given action.opt(optim.Optimizer): An optimizer for q.lr_schedule(Optional[optim.lr_scheduler._LRScheduler]): Learning rate schedule for the optimizer of q.max_grad_norm(float): Clip the norm of the gradient during backprop using this value.data_group(str): The name of the data group from which this Loss takes its data.log_per_param_weights((bool)): If true, log each individual policy parameter that is optimized (norm and value histogram).log_per_param_grads((bool)): If true, log the gradients of each individual policy parameter that is optimized (norm and histogram).
def loss(self, observation, actions, q_target) -> None
class QTarget(LoggingMixin, Callback):
Creates rolling averages of the Q nets, and predicts q values using these.
The module is responsible both for keeping the averages correct in the target q networks and supplying q-value predictions using the target q networks.
Methods
def __init__(
self
,
*pi,
ln_alpha,
q1,
q2,
q1t,
q2t,
gamma,
reward_scale,
target_q_tau,
data_group,
roll_length,
use_terminal_masking
) -> None
Arguments:
pi(nn.Module): A deep neural net that outputs actions and their log probability given a state.ln_alpha(torch.tensor): The current weight for the entropy part of the soft Q.q1(nn.Module): A deep neural net that outputs the discounted loss given the current observations and a given action.q2(nn.Module): A deep neural net that outputs the discounted loss given the current observations and a given action. :param q1t (torch.nn.Module, optional): target Q network. (default: None) :param q2t (torch.nn.Module, optional): target Q network. (default: None) :param gamma (float, optional): Discount factor for the rewards in time. (default: 0.99) :param reward_scale (float, optional): Scale factor for the rewards. (default: 1.0) :param target_q_tau (float, optional): The weight given to the latest network in the exponential moving average. So NewTargetQ = OldTargetQ * (1-tau)
- Q*tau. (default: 0.005) :param data_group (str, optional): The name of the data group from which this Loss takes its data. (default: "default") :param roll_length (int, optional): Rollout length. (default: 1) :param use_terminal_masking (bool, optional): Whether to use terminal masking for the next values. (default: False)
q1t(Optional[nn.Module])q2t(Optional[nn.Module])gamma(float)reward_scale(float)target_q_tau(float)data_group(str)roll_length(int)use_terminal_masking(bool)
def begin_batch(self, next_observation, rewards, masks) -> None
def end_batch(self) -> None
class PolicyLoss(LossCallback):
Maximize the soft Q-value for the policy. This loss modifies the policy to select the action that gives the highest soft q-value.
Methods
def __init__(
self
,
*pi,
ln_alpha,
q,
opt,
lr_schedule,
q2,
max_grad_norm,
name,
data_group,
log_per_param_weights,
log_per_param_grads
) -> None
Arguments:
pi(nn.Module): A deep neural net that outputs actions and their log probability given a state.ln_alpha(torch.tensor): The current weight for the entropy part of the soft Q.q(nn.Module): A deep neural net that outputs the discounted loss given the current observations and a given action.opt(optim.Optimizer): An optimizer for pi.lr_schedule(Optional[optim.lr_scheduler._LRScheduler]): Learning rate schedule for the optimizer of policy.q2(Optional[nn.Module]): A second deep neural net that outputs the discounted loss given the current observations and a given action. This is not necessary since it is fine if the policy isn't pessimistic, but can be nice for symmetry with the Q-loss.max_grad_norm(float): Clip the norm of the gradient during backprop using this value.name(str): The name of the module. Used e.g. while logging.data_group(str): The name of the data group from which this Loss takes its data.log_per_param_weights((bool)): If true, log each individual policy parameter that is optimized (norm and value histogram).log_per_param_grads((bool)): If true, log the gradients of each individual policy parameter that is optimized (norm and histogram).
def loss(self, observation) -> None
class AlphaLoss(LossCallback):
Tweaks the alpha so that a specific target entropy is kept. The target entropy is scaled with the number of actions and a provided entropy scaling factor.
Methods
def __init__(
self
,
*pi,
ln_alpha,
opt,
lr_schedule,
n_actions,
max_grad_norm,
max_alpha,
name,
data_group,
t_entropy
) -> None
Arguments:
pi(nn.Module): A deep neural net that outputs actions and their log probability given a state.ln_alpha(torch.tensor): The current weight for the entropy part of the soft Q. :param lr_schedule (torch.optim.lr_scheduler._LRSchedule | None): Learning rate schedule for the optimizer of alpha.opt(optim.Optimizer): An optimizer for ln_alpha.lr_schedule(optim.lr_scheduler._LRScheduler | None)n_actions(int): The dimension of the action space. Scales the target entropy.max_grad_norm(float): Clip the norm of the gradient during backprop using this value.max_alpha(float)name(str): The name of the module. Used e.g. while logging.data_group(str): The name of the data group from which this Loss takes its data. :param t_entropy (float | Schedule | None): Value or schedule for the target entropy.t_entropy(float | Schedule | None)
def loss(self, observation) -> None
def end_batch(self) -> None
def state_dict(self) -> None
def load_state_dict(
self,
state_dict,
load_weights,
load_optimizer,
load_hparams
) -> None
class AgentProxyWrapper:
Methods
def __init__(self, *inner) -> None
def __call__(self) -> None
def input_names(self) -> None
def output_names(self) -> None
def policy(self) -> None
class FeatureAgentProxy(GenericAgentProxy):
An agent proxy for basic MLPs. This AgentProxy assumes that the observations will contain a single flat array of features.
Methods
def __init__(self, policy, device, input_key) -> None
Create a new proxy.
Arguments:
policy(nn.Module): The policy to execute for actions.device(torch.device): The device to run on.input_key(str): The name of the features. (default: "obs") (default: obs)
class VisionAgentProxy(FeatureAgentProxy):
This AgentProxy assumes that the observations will contain image observations 'obs'.
Methods
def __init__(self, policy, device) -> None
Arguments:
policy(nn.Module)device(torch.device)
class MultiKeyAgentProxy(GenericAgentProxy):
Handles multiple input keys. Observations are dicts that contain multiple input keys (e.g. both "features" and "images").
Methods
def __init__(self, policy, device, input_keys, spaces) -> None
Create a new proxy.
Arguments:
policy(nn.Module): The policy to execute for actions.device(torch.device): The device to run on.input_keys(tuple): The names of the input.spaces(MDPSpace)
module emote.callback
Classes
class CallbackMeta(ABCMeta):
The CallbackMeta metaclass modifies the callbacks so that they accept data groups.
Methods
def __init__(self, cls, bases, fields) -> None
Arguments:
clsbasesfields
def __call__(self) -> None
def extend(self, func) -> None
def keys_from_member(self) -> None
class Callback:
The principal modular building block of emote. Callbacks are modular pieces of code that together build up the training loop. They contain hooks that are executed at different points during training. These can consume values from other callbacks, and generate their own for others to consume. This allows a very loosely coupled flow of data between different parts of the code. The most important examples of callbacks in emote are the Losses.
The concept has been borrowed from Keras and FastAI.
Methods
def __init__(self, cycle) -> None
Arguments:
cycle(int | None)
def restore_state(self) -> None
Called before training starts to allow loader modules to import state.
At this point, no assumptions can be made for other modules state.
def begin_training(self) -> None
Called when training starts, both from scratch and when restoring from a checkpoint.
def begin_cycle(self) -> None
Called at the start of each cycle.
def begin_batch(self) -> None
Called at the start of each batch, immediately after data has been sampled.
def backward(self) -> None
The main batch processing should happen here.
def end_batch(self) -> None
Called when the backward pass has been completed.
def end_cycle(self) -> None
Called when a callbacks cycle is completed.
def end_training(self) -> None
Called right before shutdown, if possible.
def state_dict(self) -> Dict[str, Any]
Called by checkpointers primarily to capture state for on-disk saving.
def load_state_dict(
self,
state_dict,
load_network,
load_optimizer,
load_hparams
) -> None
Called from checkpoint-loaders during the restore_state phase,
primarily.
Arguments:
state_dict(Dict[str, Any])load_network(bool)(default: True)load_optimizer(bool)(default: True)load_hparams(bool)(default: True)
class BatchCallback(Callback):
package emote.callbacks
Classes
class Checkpointer(Callback):
Checkpointer writes out a checkpoint every n steps. Exactly what is written to the checkpoint is determined by the restorees supplied in the constructor.
Methods
def __init__(
self
,
*restorees,
run_root,
checkpoint_interval,
checkpoint_index,
storage_subdirectory
) -> None
Arguments:
restorees(list[Restoree]): A list of restorees that should be saved.run_root(str): The root path to where the run artifacts should be stored.checkpoint_interval(int): Number of backprops between checkpoints.checkpoint_index(int)storage_subdirectory(str): The subdirectory where the checkpoints are stored.
def begin_training(self) -> None
def end_cycle(self, bp_step, bp_samples) -> None
class CheckpointLoader(Callback):
CheckpointLoader loads a checkpoint like the one created by Checkpointer.
This is intended for resuming training given a specific checkpoint index. It also enables you to load network weights, optimizer, or other callback hyper-params independently. If you want to do something more specific, like only restore a specific network (outside a callback), it is probably easier to just do it explicitly when the network is constructed.
Methods
def __init__(
self
,
*restorees,
run_root,
checkpoint_index,
load_weights,
load_optimizers,
load_hparams,
storage_subdirectory
) -> None
Arguments:
restorees(list[Restoree]): A list of restorees that should be restored.run_root(str): The root path to where the run artifacts should be stored.checkpoint_index(int): Which checkpoint to load.load_weights(bool): If True, it loads the network weightsload_optimizers(bool): If True, it loads the optimizer stateload_hparams(bool): If True, it loads other callback hyper- paramsstorage_subdirectory(str): The subdirectory where the checkpoints are stored.
def restore_state(self) -> None
class BackPropStepsTerminator(Callback):
Terminates training after a given number of backprops.
Methods
def __init__(self, bp_steps) -> None
Arguments:
bp_steps(int): The total number of backprops that the trainer should run for.
def end_cycle(self) -> None
class LoggingMixin:
A Mixin that accepts logging calls. Logged data is saved on this object and gets written by a Logger. This therefore doesn't care how the data is logged, it only provides a standard interface for storing the data to be handled by a Logger.
Methods
def __init__(self, *default_window_length) -> None
Arguments:
default_window_length(int)
def log_scalar(self, key, value) -> None
Use log_scalar to periodically log scalar data.
Arguments:
key(str)value(float | torch.Tensor)
def log_windowed_scalar(self, key, value) -> None
Log scalars using a moving window average.
By default this will use default_window_length from the constructor as the window
length. It can also be overridden on a per-key basis using the format
windowed[LENGTH]:foo/bar. Note that this cannot be changed between multiple invocations -
whichever length is found first will be permanent.
Arguments:
key(str)value(float | torch.Tensor | Iterable[torch.Tensor | float])
def log_image(self, key, value) -> None
Use log_image to periodically log image data.
Arguments:
key(str)value(torch.Tensor)
def log_video(self, key, value) -> None
Use log_scalar to periodically log scalar data.
Arguments:
key(str)value(Tuple[np.ndarray, int])
def log_histogram(self, key, value) -> None
def state_dict(self) -> None
def load_state_dict(
self,
state_dict,
load_network,
load_optimizer,
load_hparams
) -> None
class TensorboardLogger(Callback):
Logs the provided loggable callbacks to tensorboard.
Methods
def __init__(self, loggables, writer, log_interval, log_by_samples) -> None
Arguments:
loggables(List[LoggingMixin])writer(SummaryWriter)log_interval(int)log_by_samples(bool)
def begin_training(self, bp_step, bp_samples) -> None
def end_cycle(self, bp_step, bp_samples) -> None
class LossCallback(LoggingMixin, Callback):
Losses are callbacks that implement a loss function.
Methods
def __init__(
self,
lr_schedule
,
*name,
network,
optimizer,
max_grad_norm,
data_group,
log_per_param_weights,
log_per_param_grads
) -> None
Arguments:
lr_schedule(Optional[optim.lr_scheduler._LRScheduler])name(str)network(Optional[nn.Module])optimizer(Optional[optim.Optimizer])max_grad_norm(float)data_group(str)log_per_param_weightslog_per_param_grads
def backward(self) -> None
def log_per_param_weights_and_grads(self) -> None
def state_dict(self) -> None
def load_state_dict(
self,
state_dict,
load_weights,
load_optimizers,
load_hparams
) -> None
def loss(self) -> Tensor
The loss method needs to be overwritten to implement a loss.
Returns:
- A PyTorch tensor of shape (batch,).
module emote.callbacks.checkpointing
Classes
class Restoree(Protocol):
Fields
name:str
Methods
def state_dict(self) -> dict[str, Any]
def load_state_dict(
self,
state_dict,
load_network,
load_optimizer,
load_hparams
) -> None
class Checkpointer(Callback):
Checkpointer writes out a checkpoint every n steps. Exactly what is written to the checkpoint is determined by the restorees supplied in the constructor.
Methods
def __init__(
self
,
*restorees,
run_root,
checkpoint_interval,
checkpoint_index,
storage_subdirectory
) -> None
Arguments:
restorees(list[Restoree]): A list of restorees that should be saved.run_root(str): The root path to where the run artifacts should be stored.checkpoint_interval(int): Number of backprops between checkpoints.checkpoint_index(int)storage_subdirectory(str): The subdirectory where the checkpoints are stored.
def begin_training(self) -> None
def end_cycle(self, bp_step, bp_samples) -> None
class CheckpointLoader(Callback):
CheckpointLoader loads a checkpoint like the one created by Checkpointer.
This is intended for resuming training given a specific checkpoint index. It also enables you to load network weights, optimizer, or other callback hyper-params independently. If you want to do something more specific, like only restore a specific network (outside a callback), it is probably easier to just do it explicitly when the network is constructed.
Methods
def __init__(
self
,
*restorees,
run_root,
checkpoint_index,
load_weights,
load_optimizers,
load_hparams,
storage_subdirectory
) -> None
Arguments:
restorees(list[Restoree]): A list of restorees that should be restored.run_root(str): The root path to where the run artifacts should be stored.checkpoint_index(int): Which checkpoint to load.load_weights(bool): If True, it loads the network weightsload_optimizers(bool): If True, it loads the optimizer stateload_hparams(bool): If True, it loads other callback hyper- paramsstorage_subdirectory(str): The subdirectory where the checkpoints are stored.
def restore_state(self) -> None
class InvalidCheckpointLocation(ValueError):
module emote.callbacks.generic
Classes
class BackPropStepsTerminator(Callback):
Terminates training after a given number of backprops.
Methods
def __init__(self, bp_steps) -> None
Arguments:
bp_steps(int): The total number of backprops that the trainer should run for.
def end_cycle(self) -> None
module emote.callbacks.logging
Classes
class TensorboardLogger(Callback):
Logs the provided loggable callbacks to tensorboard.
Methods
def __init__(self, loggables, writer, log_interval, log_by_samples) -> None
Arguments:
loggables(List[LoggingMixin])writer(SummaryWriter)log_interval(int)log_by_samples(bool)
def begin_training(self, bp_step, bp_samples) -> None
def end_cycle(self, bp_step, bp_samples) -> None
class TerminalLogger(Callback):
Logs the provided loggable callbacks to the python logger.
Methods
def __init__(self, callbacks, log_interval) -> None
Arguments:
callbacks(List[LoggingMixin])log_interval(int)
def log_scalars(self, step, suffix) -> None
Logs scalar logs adding optional suffix on the first level. Example: If k='training/loss' and suffix='bp_step', k will be renamed to 'training_bp_step/loss'.
Arguments:
stepsuffix
def end_cycle(self, bp_step) -> None
module emote.callbacks.loss
Classes
class LossCallback(LoggingMixin, Callback):
Losses are callbacks that implement a loss function.
Methods
def __init__(
self,
lr_schedule
,
*name,
network,
optimizer,
max_grad_norm,
data_group,
log_per_param_weights,
log_per_param_grads
) -> None
Arguments:
lr_schedule(Optional[optim.lr_scheduler._LRScheduler])name(str)network(Optional[nn.Module])optimizer(Optional[optim.Optimizer])max_grad_norm(float)data_group(str)log_per_param_weightslog_per_param_grads
def backward(self) -> None
def log_per_param_weights_and_grads(self) -> None
def state_dict(self) -> None
def load_state_dict(
self,
state_dict,
load_weights,
load_optimizers,
load_hparams
) -> None
def loss(self) -> Tensor
The loss method needs to be overwritten to implement a loss.
Returns:
- A PyTorch tensor of shape (batch,).
module emote.callbacks.testing
Classes
class FinalLossTestCheck(Callback):
Logs the provided loggable callbacks to the python logger.
Methods
def __init__(self, callbacks, cutoffs, test_length) -> None
Arguments:
callbacks(List[LossCallback])cutoffs(List[float])test_length(int)
def end_cycle(self) -> None
class FinalRewardTestCheck(Callback):
Methods
def __init__(self, callback, cutoff, test_length, key, use_windowed) -> None
def end_cycle(self) -> None
module emote.callbacks.wb_logger
Classes
class WBLogger(Callback):
Logs the provided loggable callbacks to Weights&Biases.
Methods
def __init__(self, callbacks, config, log_interval) -> None
Arguments:
callbacks(List[LoggingMixin])config(Dict)log_interval(int)
def begin_training(self, bp_step, bp_samples) -> None
def end_cycle(self, bp_step, bp_samples) -> None
def end_training(self) -> None
package emote.env
package emote.env.box2d
Functions
def make_vision_box2d_env(
environment_id,
rank,
seed,
frame_stack,
use_float_scaling
) -> None
Arguments:
environment_id(str): (str) the environment IDrank(int): (int) an integer offset for the random seedseed(int): (int) the inital seed for RNGframe_stack(int): (int) Stacks this many frames. (default: 3)use_float_scaling(bool): (bool) scaled the observations from char to normalised float (default: True)
Returns:
- the env creator function
module emote.env.wrappers
Classes
class WarpFrame(gymnasium.ObservationWrapper):
Methods
def __init__(self, env, width, height) -> None
Warp frames to width x height.
Arguments:
env: (Gym Environment) the environmentwidth(int)(default: 84)height(int)(default: 84)
def observation(self, frame) -> None
Returns the current observation from a frame.
Arguments:
frame: ([int] or [float]) environment frame
Returns:
- ([int] or [float]) the observation
class FrameStack(gymnasium.Wrapper):
Methods
def __init__(self, env, n_frames) -> None
Stack n_frames last frames. Returns lazy array, which is much more memory efficient.
See Also
LazyFrames (Below)
Arguments:
env: (Gym Environment) the environmentn_frames(int): (int) the number of frames to stack
def reset(self) -> None
def step(self, action) -> None
class ScaledFloatFrame(gymnasium.ObservationWrapper):
class LazyFrames(object):
Methods
def __init__(self, frames) -> None
This object ensures that common frames between the observations are only stored once. It exists purely to optimize memory usage which can be huge for DQN's 1M frames replay buffers.
This object should only be converted to np.ndarray before being passed to the model.
Arguments:
frames: ([int] or [float]) environment frames
package emote.extra
module emote.extra.crud_storage
Generic CRUD-based storage on disk.
Classes
class StorageItemHandle(Generic[T]):
A handle that represents a storage item. Can be safely exposed to users. Not cryptographically safe: handles are guessable.
You can convert this handle from and to strings using str(handle) and
StorageItemHandle.from_string(string).
Fields
handle:int
Methods
def from_string(value) -> Optional['StorageItemHandle']
Parses a handle from its string representation. Returns None if the handle is invalid.
Arguments:
value(str)
class StorageItem(Generic[T]):
Fields
-
handle:StorageItemHandle[T] -
timestamp:datetime -
filepath:str
class CRUDStorage(Generic[T]):
Manages a set of files on disk in a simple CRUD way. All files will be
stored to a single directory with a name on the format
{prefix}{timestamp}_{index}.{extension}.
This class is thread-safe.
Methods
def __init__(self, directory, prefix, extension) -> None
Arguments:
directory(str)prefix(str)extension(str)(default: bin)
def create_with_data(self, data) -> StorageItem[T]
Creates a new file with the given data.
Arguments:
data(bytearray)
def create_from_filepath(self, filepath) -> StorageItem[T]
Creates a new entry for an existing file. The file must already be in the directory that this storage manages. It does not need to conform to the naming convention that the CRUDStorage normally uses.
Arguments:
filepath(str)
def create_with_saver(self, saver) -> StorageItem[T]
Creates a new file by saving it via the provided function. The function will be called with the path at which the file should be saved.
Arguments:
saver(Callable[[str], None])
def update(self, handle, data) -> None
Updates an existing file with the given contents.
Arguments:
handle(StorageItemHandle[T])data(bytearray)
def items(self) -> Sequence[StorageItem[T]]
Returns:
- a sequence of all files owned by this storage.
def delete(self, handle) -> bool
Deletes an existing file owned by this storage.
Arguments:
handle(StorageItemHandle[T])
Returns:
- True if a file was deleted, and false if the file was not owned by this storage.
def get(self, handle) -> Optional[StorageItem[T]]
Arguments:
handle(StorageItemHandle[T])
Returns:
- The storage item corresponding handle or None if it was not found
def latest(self) -> Optional[StorageItem[T]]
The last storage item that was added to the storage. If items have been deleted, this is the last item of the ones that remain.
module emote.extra.onnx_exporter
Classes
class QueuedExport:
Methods
def __init__(self, metadata) -> None
def process(self, storage) -> None
def block_until_complete(self) -> None
class OnnxExporter(LoggingMixin, Callback):
Handles onnx exports of a ML policy.
Call export whenever you want to save an onnx version of the
current model, or export_threadsafe if you're outside the
training loop.
Parameters:
Methods
def __init__(
self,
agent_proxy,
spaces,
requires_epsilon,
directory,
interval,
prefix,
device
) -> None
Arguments:
agent_proxy(AgentProxy): the agent API to exportspaces(MDPSpace): The spaces describing the model inputs and outputsrequires_epsilon(bool): If true, the API should accept an input epsilon per actiondirectory(str): path to the directory where the files should be created. If it does not exist it will be created.interval(int | None): if provided, will automatically export ONNX files at this cadence.prefix(str): all file names will have this prefix. (default: savedmodel_)device(torch.device | None): if provided, will transfer the model inputs to this device before exporting.
def add_metadata(self, key, value) -> None
def end_batch(self) -> None
def end_cycle(self) -> None
def process_pending_exports(self) -> None
If you are using export_threadsafe the main thread must call this
method regularly to make sure things are actually exported.
def export_threadsafe(self, metadata) -> StorageItem
Same as export, but it can be called in threads other than the
main thread.
This method relies on the main thread calling process_pending_exports from time to time.
You cannot call this method from the main thread. It will block indefinitely.
Arguments:
metadata
def export(self, metadata) -> StorageItem
Serializes a model to onnx and saves it to disk. This must only be called from the main thread. That is, the thread which has ownership over the model and that modifies it. This is usually the thread that has the training loop.
Arguments:
metadata
def delete(self, handle) -> bool
def get(self, handle) -> bool
def items(self) -> Sequence[StorageItem]
def latest(self) -> Optional[StorageItem]
module emote.extra.schedules
Classes
class BPStepScheduler:
Fields
-
bp_step_begin:float -
bp_step_end:float -
value_min:float -
value_max:float
Methods
def evaluate_at(self, bp) -> None
class Schedule:
Methods
def __init__(self, initial, final, steps) -> None
def value(self) -> None
def step(self) -> None
class ConstantSchedule(Schedule):
Constant value that doesn't change over time.
Methods
def __init__(self, value) -> None
Arguments:
value(float): Value of the schedule.
class LinearSchedule(Schedule):
Linear interpolation between initial and final over steps timesteps. After this many timesteps, final is returned.
Methods
def __init__(self, initial, final, steps, use_staircase, staircase_steps) -> None
Arguments:
initial(float): Initial value.final(float): Final value.steps(int): Number of steps.use_staircase(bool): Use step like decay. Defaults to False. (default: False)staircase_steps(int): The number of discrete steps. Defaults to 5. (default: 5)
def step(self) -> None
class CyclicSchedule(Schedule):
Cyclic schedule. Args: initial (float): Initial value. final (float): Final value. half_period_steps (int): Number of steps in one half of the cycle. mode (str, optional): One of {triangular, triangular2}. Defaults to "triangular".
* triangular: A basic triangular cycle without amplitude scaling.
* triangular2: A basic triangular cycle that scales initial amplitude by half each cycle.
** Note: for triangular2, the final value is the boundary that is scaled down
at each cycle iteration,
meaning that the value of the scheduled parameter will settle around initial.
Methods
def __init__(self, initial, final, half_period_steps, mode) -> None
Arguments:
initial(float)final(float)half_period_steps(int)mode(str)(default: triangular)
def step(self) -> None
class CosineAnnealing(Schedule):
Cosine annealing schedule.
Methods
def __init__(self, initial, final, steps) -> None
Arguments:
initial(float): Initial value.final(float): Final value.steps(int): Number of steps.
def step(self) -> None
class CosineAnnealingWarmRestarts(Schedule):
Cosine annealing schedule with warm restarts.
Methods
def __init__(self, initial, final, steps) -> None
Arguments:
initial(float): Initial value.final(float): Final value.steps(int): Number of steps.
def step(self) -> None
module emote.extra.system_logger
Logger that logs the memory consumption and memory consumption growth rate.
Classes
class SystemLogger(LoggingMixin, Callback):
package emote.memory
This module contains all the major building blocks for our memory
implementation. The memory was developed in the same time period as
DeepMind's Reverb <https://www.deepmind.com/open-source/reverb>_, and shares
naming with it, which in turn is borrowing from databases. What is not
alike Reverb is that we do not have the RateSamplers (but it can be
added). We also do not share data between ArrayTables.
The goal of the memory is to provide a unified interface for all types of machine learning tasks. This is achieved by focusing on configuration and pluggability over code-driven functionality.
Currently, there are three main points of customization:
- Shape and type of data
- Insertion, sampling, and eviction
- Data transformation and generation
High-level parts
ArrayTable
A table is a datastructure containing a specific type of data that shares the same high-level structure.
Columns and Virtual Columns
A column is a storage for a specific type of data where each item is the same shape and type. A virtual column is like a column, but it references another column and does data synthesization or modification w.r.t that. For example, dones and masks are synthetic data based only on indices.
Adaptors
Adaptors are another approach to virtual column but are more suited for transforming the whole batch, such as scaling for reshaping specific datas. Since this step occurs when the data has already been converted to tensors, the full power of Tensorflow is available here and gradients will be correctly tracked.
Strategies, Samplers and Ejectors
Strategies are based on the delegate pattern, where we can inject implementation details through objects instead of using inheritance. Strategies define the API for sampling and ejection from memories, and are queried from the table upon sampling and insertion.
Samplers and Ejectors track the data (but do not own it!). They are used by the table for sampling and ejection based on the policy they implement. Currently we have Fifo and Uniform samplers and ejectors, but one could have prioritized samplers/ejectors, etc.
Proxy Wrappers
Wrappers live around the memory proxy and extend functionality. This is a great point for data conversion, validation, and logging.
Classes
class MemoryTable(Protocol):
Fields
adaptors:List[Adaptor]
Methods
def sample(self, count, sequence_length) -> SampleResult
Sample COUNT traces from the memory, each consisting of SEQUENCE_LENGTH frames.
The data is transposed in a SoA fashion (since this is both easier to store and easier to consume).
Arguments:
count(int)sequence_length(int)
def size(self) -> int
Query the number of elements currently in the memory.
def full(self) -> bool
Query whether the memory is filled.
def add_sequence(self, identity, sequence) -> None
Add a fully terminated sequence to the memory.
Arguments:
identity(int)sequence
def store(self, path, version) -> bool
Persist the whole table and all metadata into the designated name.
Arguments:
path(str)version(TableSerializationVersion)
def restore(self, path, override_version) -> bool
Restore the data table from the provided path. This also clears the data stores.
Arguments:
path(str)override_version(TableSerializationVersion | None)
class MemoryTableProxy:
The sequence builder wraps a sequence-based memory to build full episodes from [identity, observation] data.
Not thread safe.
Methods
def __init__(
self,
memory_table,
minimum_length_threshold,
use_terminal
,
*name
) -> None
Arguments:
memory_table(MemoryTable)minimum_length_threshold(Optional[int])use_terminal(bool)name(str)
def name(self) -> None
def size(self) -> None
def resize(self, new_size) -> None
def store(self, path) -> None
def is_initial(self, identity) -> None
Returns true if identity is not already used in a partial sequence. Does not validate if the identity is associated with a complete episode.
Arguments:
identity(int)
def add(self, observations, responses) -> None
def timers(self) -> None
class MemoryLoader:
Methods
def __init__(
self,
memory_table,
rollout_count,
rollout_length,
size_key,
data_group
) -> None
def is_ready(self) -> None
True if the data loader has enough data to start providing data.
class MemoryExporterProxyWrapper(LoggingMixin, MemoryTableProxyWrapper):
Export the memory at regular intervals.
Methods
def __init__(
self,
memory,
target_memory_name,
inf_steps_per_memory_export,
experiment_root_path,
min_time_per_export
) -> None
Arguments:
memory(MemoryTableProxy | MemoryTableProxyWrapper)target_memory_nameinf_steps_per_memory_exportexperiment_root_path(str)min_time_per_export(int)(default: 600)
def add(self, observations, responses) -> None
First add the new batch to the memory.
Arguments:
observations(Dict[AgentId, DictObservation])responses(Dict[AgentId, DictResponse])
class MemoryImporterCallback(Callback):
Load and validate a previously exported memory.
Methods
def __init__(
self,
memory_table,
target_memory_name,
experiment_load_dir,
load_fname_override
) -> None
Arguments:
memory_table(MemoryTable)target_memory_name(str)experiment_load_dir(str)load_fname_override
def restore_state(self) -> None
class LoggingProxyWrapper(LoggingMixin, MemoryTableProxyWrapper):
Methods
def __init__(self, inner, writer, log_interval) -> None
def state_dict(self) -> dict[str, Any]
def load_state_dict(
self,
state_dict,
load_network,
load_optimizer,
load_hparams
) -> None
def add(self, observations, responses) -> None
def report(self, metrics, metrics_lists) -> None
def get_report(
self,
keys
) -> Tuple[dict[str, int | float | list[float]], dict[str, list[float]]]
class MemoryWarmup(Callback):
A blocker to ensure memory has data. This ensures the memory has enough data when training starts, as the memory will panic otherwise. This is useful if you use an async data generator.
If you do not use an async data generator this can deadlock your training loop and prevent progress.
Methods
def __init__(self, loader, exporter, shutdown_signal) -> None
Arguments:
loader(MemoryLoader)exporter(Optional[OnnxExporter])shutdown_signal(Optional[Callable[[], bool]])
def begin_training(self) -> None
class JointMemoryLoader:
A memory loader capable of loading data from multiple
MemoryLoaders.
Methods
def __init__(self, loaders, size_key) -> None
Arguments:
loaders(list[MemoryLoader])size_key(str)(default: batch_size)
def is_ready(self) -> None
module emote.memory.adaptors
Classes
class DictObsAdaptor:
Converts multiple observation columns to a single dict observation.
Methods
def __init__(self, keys, output_keys, with_next) -> None
Arguments:
keys(List[str]): The dictionary keys to extractoutput_keys(Optional[List[str]]): The output names for the extracted keys. Defaults to the same name.with_next(bool): If True, adds an extra column called "next_{key}" for each key in keys. (default: True)
def __call__(self, result, count, sequence_length) -> SampleResult
class KeyScaleAdaptor:
An adaptor to apply scaling to a specified sampled key.
Methods
def __init__(self, scale, key) -> None
Arguments:
scale: The scale factor to applykey: The key for which to scale data
def __call__(self, result, count, sequence_length) -> SampleResult
class KeyCastAdaptor:
An adaptor to cast a specified sampled key.
Methods
def __init__(self, dtype, key) -> None
Arguments:
dtype: The dtype to cast to.key: The key for which to cast data
def __call__(self, result, count, sequence_length) -> SampleResult
class TerminalAdaptor:
An adaptor to apply tags from detailed terminal tagging.
Methods
def __init__(self, target_key, value_key) -> None
Arguments:
target_key(str): the default mask data to overridevalue_key(str): the key containing the terminal mask value to apply
def __call__(self, result, count, sequence_length) -> SampleResult
module emote.memory.builder
Classes
class DictMemoryTable(ArrayMemoryTable):
Methods
def __init__(
self
,
*use_terminal_column,
obs_keys,
columns,
maxlen,
length_key,
sampler,
device
) -> None
class DictObsMemoryTable(DictMemoryTable):
Create a memory suited for Reinforcement Learning Tasks with 1-Step Bellman Backup with a single bootstrap value, and using dictionary observations as network inputs.
Methods
def __init__(
self
,
*spaces,
use_terminal_column,
maxlen,
device,
dones_dtype,
masks_dtype,
sampler
) -> None
Arguments:
spaces(MDPSpace)use_terminal_column(bool)maxlen(int)device(torch.device)dones_dtypemasks_dtypesampler(SampleStrategy)
class DictObsNStepMemoryTable(DictMemoryTable):
Create a memory suited for Reinforcement Learning Tasks with N-Step Bellman Backup with a single bootstrap value, and using dictionary observations as network inputs.
Methods
def __init__(self, *spaces, use_terminal_column, maxlen, sampler, device) -> None
Arguments:
spaces(MDPSpace)use_terminal_column(bool)maxlen(int)sampler(SampleStrategy)device(torch.device)
module emote.memory.callbacks
Classes
class MemoryImporterCallback(Callback):
Load and validate a previously exported memory.
Methods
def __init__(
self,
memory_table,
target_memory_name,
experiment_load_dir,
load_fname_override
) -> None
Arguments:
memory_table(MemoryTable)target_memory_name(str)experiment_load_dir(str)load_fname_override
def restore_state(self) -> None
module emote.memory.column
Classes
class Column:
A typed column for data storage.
Fields
-
name:str -
shape:Tuple[int] -
dtype:type
Methods
def state(self) -> None
def load_state(self, config) -> None
class TagColumn(Column):
A typed column for tag storage.
class VirtualColumn(Column):
A column providing fake or transformed data via Mapper.
Fields
-
target_name:str -
mapper:Type[VirtualStorage]
Methods
def state(self) -> None
def load_state(self, config) -> None
module emote.memory.core_types
Supporting types used for working with the memory.
Classes
class Matrix(Generic[Number]):
module emote.memory.coverage_based_strategy
Classes
class CoverageBasedStrategy(Strategy):
A sampler intended to sample based on coverage of experiences, favoring less-visited states.
This base class can be used for implementing various coverage-based sampling strategies.
Methods
def __init__(self, alpha) -> None
Arguments:
alpha(default: 0.5)
def track(self, identity, sequence_length) -> None
def forget(self, identity) -> None
class CoverageBasedSampleStrategy(CoverageBasedStrategy, SampleStrategy):
Methods
def __init__(self, alpha) -> None
def sample(self, count, transition_count) -> Sequence[SamplePoint]
class CoverageBasedEjectionStrategy(CoverageBasedStrategy, EjectionStrategy):
module emote.memory.fifo_strategy
Classes
class FifoStrategyBase(Strategy):
A sampler intended to sample in a first-in-first-out style across the whole set of experiences.
This base class is used by both the fifo sample and ejection strategies.
Methods
def __init__(self) -> None
Create a FIFO-based strategy.
def track(self, identity, sequence_length) -> None
def forget(self, identity) -> None
def post_import(self) -> None
def state(self) -> dict
Serialize the strategy to a JSON-serializable dictionary.
def load_state(self, state) -> None
Load the strategy from a dictionary.
Arguments:
state(dict)
class FifoSampleStrategy(FifoStrategyBase, SampleStrategy):
Methods
def __init__(self, per_episode, random_offset) -> None
Create a FIFO-based sample strategy.
Arguments:
per_episode(bool): if true, will only sample each episode once in a single pass (default: True)random_offset(bool): if true will sample at a random offset in each episode. Will be assumed true when sampling per episode (default: True)
def sample(self, count, transition_count) -> Sequence[SamplePoint]
class FifoEjectionStrategy(FifoStrategyBase, EjectionStrategy):
module emote.memory.loading
Utilities for loading files into memories.
Functions
def fill_table_from_legacy_file(
memory_table,
path
,
*read_obs,
read_actions,
read_rewards
) -> None
Load a legacy memory dump into a new-style table memory.
Arguments:
memory_table(ArrayMemoryTable)path(str): The path to load from. Must be a pickle file. Extension is optional :throws: OSError if file does not exist. KeyError if table or file do not match the legacy format.read_obs(bool)read_actions(bool)read_rewards(bool)
module emote.memory.memory
Sequence builder collates observations into sequences stored in the memory.
The sequence builder is the API between "instant" based APIs such as the agent proxy and the episode-based functionality of the memory implementation. The goal of the sequence builder is to consume individual timesteps per agent and collate them into episodes before submission into the memory.
Classes
class Episode:
An episode of data being constructed.
Fields
data:Dict[str, List[Matrix]]=field(default_factory=lambda : defaultdict(list))
Methods
def append(self, observation) -> Tuple
def complete(self, observation) -> Mapping[str, Matrix]
def from_initial(observation) -> Episode
class MemoryTableProxy:
The sequence builder wraps a sequence-based memory to build full episodes from [identity, observation] data.
Not thread safe.
Methods
def __init__(
self,
memory_table,
minimum_length_threshold,
use_terminal
,
*name
) -> None
Arguments:
memory_table(MemoryTable)minimum_length_threshold(Optional[int])use_terminal(bool)name(str)
def name(self) -> None
def size(self) -> None
def resize(self, new_size) -> None
def store(self, path) -> None
def is_initial(self, identity) -> None
Returns true if identity is not already used in a partial sequence. Does not validate if the identity is associated with a complete episode.
Arguments:
identity(int)
def add(self, observations, responses) -> None
def timers(self) -> None
class MemoryProxyWrapper:
Base class for memory proxy wrappers. This class forwards non-existing method accessess to the inner MemoryProxy or MemoryProxyWrapper.
Methods
def __init__(self, inner) -> None
Arguments:
inner('MemoryProxyWrapper' | MemoryProxy)
def state_dict(self) -> dict[str, Any]
def load_state_dict(
self,
state_dict,
load_network,
load_optimizer,
load_hparams
) -> None
class MemoryTableProxyWrapper(MemoryProxyWrapper):
class LoggingProxyWrapper(LoggingMixin, MemoryTableProxyWrapper):
Methods
def __init__(self, inner, writer, log_interval) -> None
def state_dict(self) -> dict[str, Any]
def load_state_dict(
self,
state_dict,
load_network,
load_optimizer,
load_hparams
) -> None
def add(self, observations, responses) -> None
def report(self, metrics, metrics_lists) -> None
def get_report(
self,
keys
) -> Tuple[dict[str, int | float | list[float]], dict[str, list[float]]]
class MemoryExporterProxyWrapper(LoggingMixin, MemoryTableProxyWrapper):
Export the memory at regular intervals.
Methods
def __init__(
self,
memory,
target_memory_name,
inf_steps_per_memory_export,
experiment_root_path,
min_time_per_export
) -> None
Arguments:
memory(MemoryTableProxy | MemoryTableProxyWrapper)target_memory_nameinf_steps_per_memory_exportexperiment_root_path(str)min_time_per_export(int)(default: 600)
def add(self, observations, responses) -> None
First add the new batch to the memory.
Arguments:
observations(Dict[AgentId, DictObservation])responses(Dict[AgentId, DictResponse])
class MemoryLoader:
Methods
def __init__(
self,
memory_table,
rollout_count,
rollout_length,
size_key,
data_group
) -> None
def is_ready(self) -> None
True if the data loader has enough data to start providing data.
class JointMemoryLoader:
A memory loader capable of loading data from multiple
MemoryLoaders.
Methods
def __init__(self, loaders, size_key) -> None
Arguments:
loaders(list[MemoryLoader])size_key(str)(default: batch_size)
def is_ready(self) -> None
class JointMemoryLoaderWithDataGroup(JointMemoryLoader):
A JointMemoryLoader that places its data inside of a user-specified datagroup.
Methods
def __init__(self, loaders, data_group, size_key) -> None
Arguments:
loaders(list[MemoryLoader])data_group(str)size_key(str)(default: batch_size)
class MemoryWarmup(Callback):
A blocker to ensure memory has data. This ensures the memory has enough data when training starts, as the memory will panic otherwise. This is useful if you use an async data generator.
If you do not use an async data generator this can deadlock your training loop and prevent progress.
Methods
def __init__(self, loader, exporter, shutdown_signal) -> None
Arguments:
loader(MemoryLoader)exporter(Optional[OnnxExporter])shutdown_signal(Optional[Callable[[], bool]])
def begin_training(self) -> None
module emote.memory.segment_tree
Classes
class SegmentTree:
Methods
def __init__(self, capacity, operation, neutral_element) -> None
Build a Segment Tree data structure. https://en.wikipedia.org/wiki/Segment_tree
Can be used as regular array, but with two important differences:
a) setting item's value is slightly slower.
It is O(lg capacity) instead of O(1).
b) user has access to an efficient ( O(log segment size) )
`reduce` operation which reduces `operation` over
a contiguous subsequence of items in the array.
Arguments:
capacity: (int) Total size of the array - must be a power of two.operation: (lambda (Any, Any): Any) operation for combining elements (eg. sum, max) must form a mathematical group together with the set of possible values for array elements (i.e. be associative)neutral_element: (Any) neutral element for the operation above. eg. float('-inf') for max and 0 for sum.
def reduce(self, start, end) -> None
Returns result of applying self.operation to a contiguous
subsequence of the array.
self.operation(arr[start], operation(arr[start+1], operation(... arr[end])))
Arguments:
start: (int) beginning of the subsequenceend: (int) end of the subsequences
Returns:
- (Any) result of reducing self.operation over the specified range of array elements.
class SumSegmentTree(SegmentTree):
Methods
def __init__(self, capacity) -> None
def sum(self, start, end) -> None
Returns arr[start] + ... + arr[end]
Arguments:
start: (int) start position of the reduction (must be >= 0)end: (int) end position of the reduction (must be < len(arr), can be None for len(arr) - 1)
Returns:
- (Any) reduction of SumSegmentTree
def find_prefixsum_idx(self, prefixsum) -> None
Find the highest index i in the array such that
sum(arr[0] + arr[1] + ... + arr[i - i]) <= prefixsum
if array values are probabilities, this function allows to sample indexes according to the discrete probability efficiently.
Arguments:
prefixsum: (float) upperbound on the sum of array prefix
Returns:
- (int) highest index satisfying the prefixsum constraint
class MinSegmentTree(SegmentTree):
Methods
def __init__(self, capacity) -> None
def min(self, start, end) -> None
Returns min(arr[start], ..., arr[end])
Arguments:
start: (int) start position of the reduction (must be >= 0)end: (int) end position of the reduction (must be < len(arr), can be None for len(arr) - 1)
Returns:
- (Any) reduction of MinSegmentTree
module emote.memory.storage
Classes
class BaseStorage(dict):
A simple dictionary-based storage with support for a temporary workspace for sampled data.
Methods
def __init__(self, shape, dtype) -> None
Arguments:
shapedtype
def get_empty_storage(self, count, length) -> None
A workspace that can be reused to skip reallocating the same numpy buffer each time the memory is sampled.
Will not work if the memory is sampled from multiple threads.
Arguments:
countlength
def sequence_length_transform(self, length) -> None
def post_import(self) -> None
class TagProxy:
Methods
def shape(self) -> None
def __init__(self, shape, dtype) -> None
def get_empty_storage(self, count, length) -> None
A workspace that can be reused to skip reallocating the same numpy buffer each time the memory is sampled.
Will not work if the memory is sampled from multiple threads.
Arguments:
countlength
def sequence_length_transform(self, length) -> None
def post_import(self) -> None
def shape(self) -> None
class VirtualStorage:
A virtual storage uses a simple storage to generate data.
Methods
def __init__(self, storage, shape, dtype) -> None
Arguments:
storageshapedtype
def shape(self) -> None
def sequence_length_transform(self, length) -> None
def get_empty_storage(self, count, length) -> None
def post_import(self) -> None
class LastWrapper:
Methods
def __init__(self, item) -> None
def shape(self) -> None
def __init__(self, item) -> None
def shape(self) -> None
def __init__(self, storage, shape, dtype, only_last) -> None
def sequence_length_transform(self, length) -> None
def with_only_last(storage, shape, dtype) -> None
class Wrapper:
Methods
def __init__(self, item, n) -> None
def shape(self) -> None
def __init__(self, storage, shape, dtype) -> None
def sequence_length_transform(self, length) -> None
def with_n(n) -> None
class MaskWrapper(Wrapper):
Methods
def __init__(self, length, shape, dtype) -> None
def shape(self) -> None
def __init__(self, storage, shape, dtype, mask) -> None
def as_mask(storage, shape, dtype) -> None
module emote.memory.strategy
Classes
class Strategy(ABC):
A generalized strategy that may be specialized for sampling or ejection from a memory buffer.
Methods
def __init__(self) -> None
def track(self, identity, sequence_length) -> None
Track a sequence given by identity and sequence_length that exists in the memory.
Arguments:
identity(int): an identity that is globally uniquesequence_length(int): the number of transitions in the sequence identified by identity
def forget(self, identity) -> None
Forget the sequence of transitions given by identity.
Arguments:
identity(int)
def on_sample(self, ids_and_offsets, transition_count, advantages) -> None
Called after a sampling strategy has been invoked, to give the strategy a chance to update sampling weights in case it uses prioritized sampling.
Arguments:
ids_and_offsets(Sequence[SamplePoint])transition_count(int)advantages(Optional[Matrix])
def post_import(self) -> None
Post-import validation of invariants and cleanup. This has to forget any imported negative ids, anything else is implementation-defined.
def state(self) -> dict
Serialize the strategy state to a dictionary.
def load_state(self, state) -> None
Load the strategy state from a dictionary.
Arguments:
state(dict)
def clear(self) -> None
Clear the strategy's internal state.
def begin_simple_import(self) -> None
Called before a simple import, to allow the strategy to prepare itself.
def end_simple_import(self) -> None
Called after a simple import, to allow the strategy to cleanup.
class SampleStrategy(Strategy):
A strategy specialized for sampling.
Methods
def sample(self, count, transition_count) -> Sequence[SamplePoint]
Apply the sampling strategy to the memory metadata, returning
count identities and offsets to use when sampling from the memory.
Arguments:
count(int)transition_count(int)
class EjectionStrategy(Strategy):
A strategy specialized for ejection sampling.
Methods
def sample(self, count) -> Sequence[int]
Apply the sampling strategy to the memory metadata, returning a list of identities that shall be ejected from the memory to remove at least "count" transitions.
Arguments:
count(int)
module emote.memory.table
Classes
class TableSerializationVersion(enum.Enum):
The version of the memory serialization format.
class MemoryTable(Protocol):
Fields
adaptors:List[Adaptor]
Methods
def sample(self, count, sequence_length) -> SampleResult
Sample COUNT traces from the memory, each consisting of SEQUENCE_LENGTH frames.
The data is transposed in a SoA fashion (since this is both easier to store and easier to consume).
Arguments:
count(int)sequence_length(int)
def size(self) -> int
Query the number of elements currently in the memory.
def full(self) -> bool
Query whether the memory is filled.
def add_sequence(self, identity, sequence) -> None
Add a fully terminated sequence to the memory.
Arguments:
identity(int)sequence
def store(self, path, version) -> bool
Persist the whole table and all metadata into the designated name.
Arguments:
path(str)version(TableSerializationVersion)
def restore(self, path, override_version) -> bool
Restore the data table from the provided path. This also clears the data stores.
Arguments:
path(str)override_version(TableSerializationVersion | None)
class ArrayMemoryTable:
Methods
def __init__(
self
,
*columns,
maxlen,
sampler,
ejector,
length_key,
adaptors,
device
) -> None
Create the table with the specified configuration.
Arguments:
columns(Sequence[Column])maxlen(int)sampler(SampleStrategy)ejector(EjectionStrategy)length_keyadaptors(Optional[Adaptor])device(torch.device)
def resize(self, new_size) -> None
def clear(self) -> None
Clear and reset all data.
def sample(self, count, sequence_length) -> SampleResult
Sample COUNT traces from the memory, each consisting of SEQUENCE_LENGTH transitions.
The transitions are returned in a SoA fashion (since this is both easier to store and easier to consume)
Arguments:
count(int)sequence_length(int)
def size(self) -> int
Query the number of elements currently in the memory.
def full(self) -> bool
Returns true if the memory has reached saturation, e.g., where new adds may cause ejection.
.. warning:: This does not necessarily mean that size() == maxlen, as
we store and eject full sequences. The memory only guarantees we will
have fewer samples than maxlen.
def add_sequence(self, identity, sequence) -> None
def store(self, path, version) -> bool
Persist the whole table and all metadata into the designated name.
Arguments:
path(str): The path to store the data to.version(TableSerializationVersion): The serialization version to use.
def restore(self, path, override_version) -> bool
module emote.memory.uniform_strategy
Classes
class UniformStrategyBase(Strategy):
A sampler intended to sample uniformly across the whole set of experiences.
This base class is used by both the uniform sample and ejection strategies.
Methods
def __init__(self) -> None
def track(self, identity, sequence_length) -> None
def forget(self, identity) -> None
def post_import(self) -> None
class UniformSampleStrategy(UniformStrategyBase, SampleStrategy):
class UniformEjectionStrategy(UniformStrategyBase, EjectionStrategy):
package emote.mixins
Mixins for emote.
Mixins are used to add functionality to other classes just like regular inheritance. The difference is that mixins are designed to work well with multiple inheritance, which requires extra care to avoid issues in initialization order.
module emote.mixins.logging
Classes
class LoggingMixin:
A Mixin that accepts logging calls. Logged data is saved on this object and gets written by a Logger. This therefore doesn't care how the data is logged, it only provides a standard interface for storing the data to be handled by a Logger.
Methods
def __init__(self, *default_window_length) -> None
Arguments:
default_window_length(int)
def log_scalar(self, key, value) -> None
Use log_scalar to periodically log scalar data.
Arguments:
key(str)value(float | torch.Tensor)
def log_windowed_scalar(self, key, value) -> None
Log scalars using a moving window average.
By default this will use default_window_length from the constructor as the window
length. It can also be overridden on a per-key basis using the format
windowed[LENGTH]:foo/bar. Note that this cannot be changed between multiple invocations -
whichever length is found first will be permanent.
Arguments:
key(str)value(float | torch.Tensor | Iterable[torch.Tensor | float])
def log_image(self, key, value) -> None
Use log_image to periodically log image data.
Arguments:
key(str)value(torch.Tensor)
def log_video(self, key, value) -> None
Use log_scalar to periodically log scalar data.
Arguments:
key(str)value(Tuple[np.ndarray, int])
def log_histogram(self, key, value) -> None
def state_dict(self) -> None
def load_state_dict(
self,
state_dict,
load_network,
load_optimizer,
load_hparams
) -> None
package emote.models
Classes
class DynamicModel(nn.Module):
Wrapper class for model. DynamicModel class functions as a wrapper for models including ensembles. It also provides data manipulations that are common when using dynamics models with observations and actions (e.g., predicting delta observations, input normalization).
Methods
def __init__(self, *model, learned_rewards, obs_process_fn, no_delta_list) -> None
Arguments:
model(nn.Module): the model to wrap.learned_rewards(bool): if True, the wrapper considers the last output of the model to correspond to reward predictions.obs_process_fn(Optional[nn.Module]): if provided, observations will be passed through this function before being given to the model.no_delta_list(Optional[list[int]]): if provided, represents a list of dimensions over which the model predicts the actual observation and not just a delta.
def forward(self, x) -> tuple[torch.Tensor, ...]
Computes the output of the dynamics model.
Arguments:
x(torch.Tensor): input
Returns:
- (tuple of tensors): predicted tensors
def loss(self, obs, next_obs, action, reward) -> tuple[torch.Tensor, dict[str, any]]
Computes the model loss over a batch of transitions.
Arguments:
obs(torch.Tensor): current observationsnext_obs(torch.Tensor): next observationsaction(torch.Tensor): actionsreward(torch.Tensor): rewards
Returns:
- (tensor and optional dict): the loss tensor and optional info
def sample(
self,
action,
observation,
rng
) -> tuple[torch.Tensor, Optional[torch.Tensor]]
Samples a simulated transition from the dynamics model. The function first normalizes the inputs to the model, and then denormalize the model output as the final output.
Arguments:
action(torch.Tensor): the action at.observation(torch.Tensor): the observation/state st.rng(torch.Generator): a random number generator.
Returns:
- predicted observation and rewards.
def get_model_input(self, obs, action) -> torch.Tensor
The function prepares the input to the neural network model by concatenating observations and actions. In case, obs_process_fn is given, the observations are processed by the function prior to the concatenation.
Arguments:
obs(torch.Tensor): observation tensoraction(torch.Tensor): action tensor
Returns:
- the concatenation of obs and actions
def process_batch(
self,
obs,
next_obs,
action,
reward
) -> tuple[torch.Tensor, torch.Tensor]
The function processes the given batch, normalizes inputs and targets, and prepares them for the training.
Arguments:
obs(torch.Tensor): the observations tensornext_obs(torch.Tensor): the next observation tensoraction(torch.Tensor): the actions tensorreward(torch.Tensor): the rewards tensor
Returns:
- (tuple[torch.Tensor, torch.Tensor]): the training input and target tensors
def save(self, save_dir) -> None
Saving the model.
Arguments:
save_dir(str): the directory to save the model
def load(self, load_dir) -> None
Loading the model.
Arguments:
load_dir(str): the directory to load the model
class ModelLoss(LossCallback):
Trains a dynamic model by minimizing the model loss.
Methods
def __init__(
self
,
*model,
opt,
lr_schedule,
max_grad_norm,
name,
data_group,
input_key
) -> None
Arguments:
model(DynamicModel): A dynamic modelopt(optim.Optimizer): An optimizer.lr_schedule(Optional[optim.lr_scheduler._LRScheduler]): A learning rate schedulermax_grad_norm(float): Clip the norm of the gradient during backprop using this value.name(str): The name of the module. Used e.g. while logging.data_group(str): The name of the data group from which this Loss takes its data.input_key(str)
def loss(self, observation, next_observation, actions, rewards) -> None
class ModelEnv:
Wraps a dynamics model into a gym-like environment.
Methods
def __init__(
self
,
*num_envs,
model,
termination_fn,
reward_fn,
generator,
input_key
) -> None
Arguments:
num_envs(int): the number of envs to simulate in parallel (batch_size).model(DynamicModel): the dynamic model to wrap.termination_fn(TermFnType): a function that receives observations, and returns a boolean flag indicating whether the episode should end or not.reward_fn(Optional[RewardFnType]): a function that receives actions and observations and returns the value of the resulting reward in the environment.generator(Optional[torch.Generator]): a torch random number generatorinput_key(str)
def reset(self, initial_obs_batch, len_rollout) -> None
Resets the model environment.
Arguments:
initial_obs_batch(torch.Tensor): a batch of initial observations.len_rollout(int): the max length of the model rollout
def step(self, actions) -> tuple[Tensor, Tensor, Tensor, dict[str, Tensor]]
Steps the model environment with the given batch of actions.
Arguments:
actions(np.ndarray): the actions for each "episode" to rollout. Shape must be batch_size x dim_actions. If a np.ndarray is given, it's converted to a torch.Tensor and sent to the model device.
Returns:
- (tuple | dict): contains the predicted next observation, reward, done flag. The done flag and rewards are computed using the termination_fn and reward_fn passed in the constructor. The rewards can also be predicted by the model.
def dict_step(
self,
actions
) -> tuple[dict[AgentId, DictObservation], dict[str, float]]
The function to step the Gym-like model with dict_action.
Arguments:
actions(dict[AgentId, DictResponse]): the dict actions.
Returns:
- (tuple[dict[AgentId, DictObservation], dict[str, float]]): the predicted next dict observation, reward, and done flag.
def dict_reset(self, obs, len_rollout) -> dict[AgentId, DictObservation]
Resets the model env.
Arguments:
obs(torch.Tensor): the initial observations.len_rollout(int): the max rollout length
Returns:
- the formatted initial observation.
class EnsembleOfGaussian(nn.Module):
Methods
def __init__(
self
,
*in_size,
out_size,
device,
num_layers,
ensemble_size,
hidden_size,
learn_logvar_bounds,
deterministic
) -> None
def default_forward(self, x) -> tuple[torch.Tensor, torch.Tensor]
def forward(self, x) -> tuple[torch.Tensor, torch.Tensor]
Computes mean and logvar predictions for the given input.
Arguments:
x(torch.Tensor): the input to the model.
Returns:
- (tuple of two tensors): the predicted mean and log variance of the output.
def loss(self, model_in, target) -> tuple[torch.Tensor, dict[str, any]]
Computes Gaussian NLL loss.
Arguments:
model_in(torch.Tensor): input tensor.target(Optional[torch.Tensor]): target tensor.
Returns:
- (a tuple of tensor and dict): a loss tensor and a dict which includes extra info.
def sample(self, model_input, rng) -> torch.Tensor
Samples next observation, reward and terminal from the model using the ensemble.
Arguments:
model_input(torch.Tensor): the observation and action.rng(torch.Generator): a random number generator.
Returns:
- predicted observation, rewards, terminal indicator and model state dictionary.
def save(self, save_dir) -> None
Saves the model to the given directory.
Arguments:
save_dir(str)
def load(self, load_dir) -> None
Loads the model from the given path.
Arguments:
load_dir(str)
class ModelBasedCollector(LoggingMixin, BatchCallback):
ModelBasedCollector class is used to sample rollouts from the trained dynamic model. The rollouts are stored in a replay buffer memory.
Arguments: model_env: The Gym-like dynamic model agent: The policy used to sample actions memory: The memory to store the new synthetic samples rollout_scheduler: A scheduler used to set the rollout-length when unrolling the dynamic model num_bp_to_retain_buffer: The number of BP steps to keep samples. Samples will be over-written (first in first out) for bp steps larger than this. data_group: The data group to receive data from. This must be set to get real (Gym) samples
Methods
def __init__(
self,
model_env,
agent,
memory,
rollout_scheduler,
num_bp_to_retain_buffer,
data_group,
input_key
) -> None
Arguments:
model_env(ModelEnv)agent(AgentProxy)memory(MemoryProxy)rollout_scheduler(BPStepScheduler)num_bp_to_retain_buffer(default: 1000000)data_group(str)(default: default)input_key(str)(default: obs)
def begin_batch(self) -> None
def get_batch(self, observation) -> None
def collect_sample(self) -> None
Collect a single rollout.
def update_rollout_size(self) -> None
class BatchSampler(BatchCallback):
BatchSampler class is used to provide batches of data for the RL training callbacks. In every BP step, it samples one batch from either the gym buffer or the model buffer based on a Bernoulli probability distribution. It outputs the batch to a separate data-group which will be used by other RL training callbacks.
Arguments: dataloader (MemoryLoader): the dataloader to load data from the model buffer prob_scheduler (BPStepScheduler): the scheduler to update the prob of data samples to come from the model vs. the Gym buffer data_group (str): the data_group to receive data rl_data_group (str): the data_group to upload data for RL training generator (torch.Generator (optional)): an optional random generator
Methods
def __init__(
self,
dataloader,
prob_scheduler,
data_group,
rl_data_group,
generator
) -> None
Arguments:
dataloader(MemoryLoader)prob_scheduler(BPStepScheduler)data_group(str)(default: default)rl_data_group(str)(default: rl_buffer)generator(Optional[torch.Generator])
def begin_batch(self) -> None
Generates a batch of data either by sampling from the model buffer or by cloning the input batch
Returns:
- the batch of data
def sample_model_batch(self) -> None
Samples a batch of data from the model buffer
Returns:
- batch samples
def use_model_batch(self) -> None
Decides if batch should come from the model-generated buffer
Returns:
- True if model samples should be used, False otherwise.
class LossProgressCheck(LoggingMixin, BatchCallback):
Methods
def __init__(self, model, num_bp, data_group, input_key) -> None
def begin_batch(self) -> None
def end_cycle(self) -> None
def get_batch(self, observation, next_observation, actions, rewards) -> None
class DeterministicModel(nn.Module):
Methods
def __init__(self, in_size, out_size, device, hidden_size, num_hidden_layers) -> None
def forward(self, x) -> torch.Tensor
def loss(self, model_in, target) -> tuple[torch.Tensor, dict[str, any]]
def sample(self, model_input, rng) -> torch.Tensor
Samples next observation, reward and terminal from the model.
Arguments:
model_input(torch.Tensor): the observation and action.rng(torch.Generator): a random number generator.
Returns:
- predicted observation, rewards, terminal indicator and model state dictionary.
module emote.models.callbacks
Classes
class ModelLoss(LossCallback):
Trains a dynamic model by minimizing the model loss.
Methods
def __init__(
self
,
*model,
opt,
lr_schedule,
max_grad_norm,
name,
data_group,
input_key
) -> None
Arguments:
model(DynamicModel): A dynamic modelopt(optim.Optimizer): An optimizer.lr_schedule(Optional[optim.lr_scheduler._LRScheduler]): A learning rate schedulermax_grad_norm(float): Clip the norm of the gradient during backprop using this value.name(str): The name of the module. Used e.g. while logging.data_group(str): The name of the data group from which this Loss takes its data.input_key(str)
def loss(self, observation, next_observation, actions, rewards) -> None
class LossProgressCheck(LoggingMixin, BatchCallback):
Methods
def __init__(self, model, num_bp, data_group, input_key) -> None
def begin_batch(self) -> None
def end_cycle(self) -> None
def get_batch(self, observation, next_observation, actions, rewards) -> None
class BatchSampler(BatchCallback):
BatchSampler class is used to provide batches of data for the RL training callbacks. In every BP step, it samples one batch from either the gym buffer or the model buffer based on a Bernoulli probability distribution. It outputs the batch to a separate data-group which will be used by other RL training callbacks.
Arguments: dataloader (MemoryLoader): the dataloader to load data from the model buffer prob_scheduler (BPStepScheduler): the scheduler to update the prob of data samples to come from the model vs. the Gym buffer data_group (str): the data_group to receive data rl_data_group (str): the data_group to upload data for RL training generator (torch.Generator (optional)): an optional random generator
Methods
def __init__(
self,
dataloader,
prob_scheduler,
data_group,
rl_data_group,
generator
) -> None
Arguments:
dataloader(MemoryLoader)prob_scheduler(BPStepScheduler)data_group(str)(default: default)rl_data_group(str)(default: rl_buffer)generator(Optional[torch.Generator])
def begin_batch(self) -> None
Generates a batch of data either by sampling from the model buffer or by cloning the input batch
Returns:
- the batch of data
def sample_model_batch(self) -> None
Samples a batch of data from the model buffer
Returns:
- batch samples
def use_model_batch(self) -> None
Decides if batch should come from the model-generated buffer
Returns:
- True if model samples should be used, False otherwise.
class ModelBasedCollector(LoggingMixin, BatchCallback):
ModelBasedCollector class is used to sample rollouts from the trained dynamic model. The rollouts are stored in a replay buffer memory.
Arguments: model_env: The Gym-like dynamic model agent: The policy used to sample actions memory: The memory to store the new synthetic samples rollout_scheduler: A scheduler used to set the rollout-length when unrolling the dynamic model num_bp_to_retain_buffer: The number of BP steps to keep samples. Samples will be over-written (first in first out) for bp steps larger than this. data_group: The data group to receive data from. This must be set to get real (Gym) samples
Methods
def __init__(
self,
model_env,
agent,
memory,
rollout_scheduler,
num_bp_to_retain_buffer,
data_group,
input_key
) -> None
Arguments:
model_env(ModelEnv)agent(AgentProxy)memory(MemoryProxy)rollout_scheduler(BPStepScheduler)num_bp_to_retain_buffer(default: 1000000)data_group(str)(default: default)input_key(str)(default: obs)
def begin_batch(self) -> None
def get_batch(self, observation) -> None
def collect_sample(self) -> None
Collect a single rollout.
def update_rollout_size(self) -> None
module emote.models.ensemble
Functions
def truncated_normal_init(m) -> None
Initializes the weights of the given module using a truncated normal distribution.
Arguments:
m(nn.Module)
Classes
class EnsembleLinearLayer(nn.Module):
Linear layer for ensemble models.
Methods
def __init__(self, num_members, in_size, out_size) -> None
Arguments:
num_members(int): the ensemble sizein_size(int): the input size of the modelout_size(int): the output size of the model
def forward(self, x) -> None
class EnsembleOfGaussian(nn.Module):
Methods
def __init__(
self
,
*in_size,
out_size,
device,
num_layers,
ensemble_size,
hidden_size,
learn_logvar_bounds,
deterministic
) -> None
def default_forward(self, x) -> tuple[torch.Tensor, torch.Tensor]
def forward(self, x) -> tuple[torch.Tensor, torch.Tensor]
Computes mean and logvar predictions for the given input.
Arguments:
x(torch.Tensor): the input to the model.
Returns:
- (tuple of two tensors): the predicted mean and log variance of the output.
def loss(self, model_in, target) -> tuple[torch.Tensor, dict[str, any]]
Computes Gaussian NLL loss.
Arguments:
model_in(torch.Tensor): input tensor.target(Optional[torch.Tensor]): target tensor.
Returns:
- (a tuple of tensor and dict): a loss tensor and a dict which includes extra info.
def sample(self, model_input, rng) -> torch.Tensor
Samples next observation, reward and terminal from the model using the ensemble.
Arguments:
model_input(torch.Tensor): the observation and action.rng(torch.Generator): a random number generator.
Returns:
- predicted observation, rewards, terminal indicator and model state dictionary.
def save(self, save_dir) -> None
Saves the model to the given directory.
Arguments:
save_dir(str)
def load(self, load_dir) -> None
Loads the model from the given path.
Arguments:
load_dir(str)
module emote.models.model
Classes
class DynamicModel(nn.Module):
Wrapper class for model. DynamicModel class functions as a wrapper for models including ensembles. It also provides data manipulations that are common when using dynamics models with observations and actions (e.g., predicting delta observations, input normalization).
Methods
def __init__(self, *model, learned_rewards, obs_process_fn, no_delta_list) -> None
Arguments:
model(nn.Module): the model to wrap.learned_rewards(bool): if True, the wrapper considers the last output of the model to correspond to reward predictions.obs_process_fn(Optional[nn.Module]): if provided, observations will be passed through this function before being given to the model.no_delta_list(Optional[list[int]]): if provided, represents a list of dimensions over which the model predicts the actual observation and not just a delta.
def forward(self, x) -> tuple[torch.Tensor, ...]
Computes the output of the dynamics model.
Arguments:
x(torch.Tensor): input
Returns:
- (tuple of tensors): predicted tensors
def loss(self, obs, next_obs, action, reward) -> tuple[torch.Tensor, dict[str, any]]
Computes the model loss over a batch of transitions.
Arguments:
obs(torch.Tensor): current observationsnext_obs(torch.Tensor): next observationsaction(torch.Tensor): actionsreward(torch.Tensor): rewards
Returns:
- (tensor and optional dict): the loss tensor and optional info
def sample(
self,
action,
observation,
rng
) -> tuple[torch.Tensor, Optional[torch.Tensor]]
Samples a simulated transition from the dynamics model. The function first normalizes the inputs to the model, and then denormalize the model output as the final output.
Arguments:
action(torch.Tensor): the action at.observation(torch.Tensor): the observation/state st.rng(torch.Generator): a random number generator.
Returns:
- predicted observation and rewards.
def get_model_input(self, obs, action) -> torch.Tensor
The function prepares the input to the neural network model by concatenating observations and actions. In case, obs_process_fn is given, the observations are processed by the function prior to the concatenation.
Arguments:
obs(torch.Tensor): observation tensoraction(torch.Tensor): action tensor
Returns:
- the concatenation of obs and actions
def process_batch(
self,
obs,
next_obs,
action,
reward
) -> tuple[torch.Tensor, torch.Tensor]
The function processes the given batch, normalizes inputs and targets, and prepares them for the training.
Arguments:
obs(torch.Tensor): the observations tensornext_obs(torch.Tensor): the next observation tensoraction(torch.Tensor): the actions tensorreward(torch.Tensor): the rewards tensor
Returns:
- (tuple[torch.Tensor, torch.Tensor]): the training input and target tensors
def save(self, save_dir) -> None
Saving the model.
Arguments:
save_dir(str): the directory to save the model
def load(self, load_dir) -> None
Loading the model.
Arguments:
load_dir(str): the directory to load the model
class DeterministicModel(nn.Module):
Methods
def __init__(self, in_size, out_size, device, hidden_size, num_hidden_layers) -> None
def forward(self, x) -> torch.Tensor
def loss(self, model_in, target) -> tuple[torch.Tensor, dict[str, any]]
def sample(self, model_input, rng) -> torch.Tensor
Samples next observation, reward and terminal from the model.
Arguments:
model_input(torch.Tensor): the observation and action.rng(torch.Generator): a random number generator.
Returns:
- predicted observation, rewards, terminal indicator and model state dictionary.
class Normalizer:
Class that keeps a running mean and variance and normalizes data accordingly.
Methods
def __init__(self) -> None
def update_stats(self, data) -> None
Updates the stored statistics using the given data.
Arguments:
data(torch.Tensor): The data used to compute the statistics.
def normalize(self, val, update_state) -> torch.Tensor
Normalizes the value according to the stored statistics.
Arguments:
val(torch.Tensor): The value to normalize.update_state(bool): Update state?
Returns:
- The normalized value.
def denormalize(self, val) -> torch.Tensor
De-normalizes the value according to the stored statistics.
Arguments:
val(torch.Tensor): The value to de-normalize.
Returns:
- The de-normalized value.
module emote.models.model_env
Classes
class ModelEnv:
Wraps a dynamics model into a gym-like environment.
Methods
def __init__(
self
,
*num_envs,
model,
termination_fn,
reward_fn,
generator,
input_key
) -> None
Arguments:
num_envs(int): the number of envs to simulate in parallel (batch_size).model(DynamicModel): the dynamic model to wrap.termination_fn(TermFnType): a function that receives observations, and returns a boolean flag indicating whether the episode should end or not.reward_fn(Optional[RewardFnType]): a function that receives actions and observations and returns the value of the resulting reward in the environment.generator(Optional[torch.Generator]): a torch random number generatorinput_key(str)
def reset(self, initial_obs_batch, len_rollout) -> None
Resets the model environment.
Arguments:
initial_obs_batch(torch.Tensor): a batch of initial observations.len_rollout(int): the max length of the model rollout
def step(self, actions) -> tuple[Tensor, Tensor, Tensor, dict[str, Tensor]]
Steps the model environment with the given batch of actions.
Arguments:
actions(np.ndarray): the actions for each "episode" to rollout. Shape must be batch_size x dim_actions. If a np.ndarray is given, it's converted to a torch.Tensor and sent to the model device.
Returns:
- (tuple | dict): contains the predicted next observation, reward, done flag. The done flag and rewards are computed using the termination_fn and reward_fn passed in the constructor. The rewards can also be predicted by the model.
def dict_step(
self,
actions
) -> tuple[dict[AgentId, DictObservation], dict[str, float]]
The function to step the Gym-like model with dict_action.
Arguments:
actions(dict[AgentId, DictResponse]): the dict actions.
Returns:
- (tuple[dict[AgentId, DictObservation], dict[str, float]]): the predicted next dict observation, reward, and done flag.
def dict_reset(self, obs, len_rollout) -> dict[AgentId, DictObservation]
Resets the model env.
Arguments:
obs(torch.Tensor): the initial observations.len_rollout(int): the max rollout length
Returns:
- the formatted initial observation.
package emote.nn
Functions
def ortho_init_(m, gain) -> None
Classes
class ActionValueMlp(nn.Module):
Methods
def __init__(self, observation_dim, action_dim, hidden_dims) -> None
def forward(self, action, obs) -> Tensor
class GaussianMlpPolicy(nn.Module):
Methods
def __init__(self, observation_dim, action_dim, hidden_dims) -> None
def forward(self, obs, epsilon) -> Tensor | Tuple[Tensor]
class GaussianPolicyHead(nn.Module):
Methods
def __init__(self, hidden_dim, action_dim) -> None
def forward(self, x, epsilon) -> Tensor | Tuple[Tensor]
Sample pre-actions and associated log-probabilities.
Arguments:
x(Tensor)epsilon(Tensor | None)
Returns:
- Direct samples (pre-actions) from the policy log- probabilities associated to those samples
module emote.nn.action_value_mlp
Classes
class ActionValueMlp(nn.Module):
Methods
def __init__(self, observation_dim, action_dim, hidden_dims) -> None
def forward(self, action, obs) -> Tensor
class SharedEncoderActionValueNet(nn.Module):
Methods
def __init__(self, shared_enc, encoder_out_dim, action_dim, hidden_dims) -> None
def forward(self, action, obs) -> None
module emote.nn.curl
Functions
def soft_update_from_to(source_params, target_params, tau) -> None
def rand_uniform(minval, maxval, shape) -> None
Classes
class ImageAugmentor:
Methods
def __init__(
self,
device,
use_fast_augment,
use_noise_aug,
use_per_image_mask_size,
min_mask_relative_size,
max_mask_relative_size
) -> None
def __call__(self, image) -> None
class CurlLoss(LossCallback):
Contrastive Unsupervised Representations for Reinforcement Learning (CURL).
paper: https://arxiv.org/abs/2004.04136
Methods
def __init__(
self,
encoder_model,
target_encoder_model,
device,
learning_rate,
learning_rate_start_frac,
learning_rate_end_frac,
learning_rate_steps,
max_grad_norm,
data_group,
desired_zdim,
tau,
use_noise_aug,
temperature,
use_temperature_variant,
use_per_image_mask_size,
use_fast_augment,
use_projection_layer,
augment_anchor_and_pos,
log_images
) -> None
Arguments:
encoder_model(Conv2dEncoder): (Conv2dEncoder) The image encoder that will be trained using CURL.target_encoder_model(Conv2dEncoder): (Conv2dEncoder) The target image encoder.device(torch.DeviceObjType): (torch.device) The device to use for computation.learning_rate(float): (float)learning_rate_start_frac(float): (float) The start fraction for LR schedule. (default: 1.0)learning_rate_end_frac(float): (float) The end fraction for LR schedule. (default: 1.0)learning_rate_steps(float): (int) The number of step to decay the LR over. (default: 1)max_grad_norm(float): (float) The maximum gradient norm, use for gradient clipping. (default: 1.0)data_group(str)(default: default)desired_zdim(int): (int) The size of the latent. If the projection layer is not used this will default to the encoder output size. (default: 128)tau(float): (float) The tau value that is used for updating the target encoder. (default: 0.005)use_noise_aug(bool): (bool) Add noise during image augmentation.temperature(float): (float) The value used for the temperature scaled cross-entropy calculation. (default: 0.1)use_temperature_variant(bool): (bool) Use normalised temperature scaled cross-entropy variant. (default: True)use_per_image_mask_size(bool): (bool) Use different mask sizes for every image in the batch.use_fast_augment(bool): (bool) A gpu compatible image augmentation that uses a fixed cutout position and size per batch.use_projection_layer(bool): (bool) Add an additional dense layer to the encoder that projects to zdim size. (default: True)augment_anchor_and_pos(bool): (bool) Augment both the anchor and positive images. (default: True)log_images(bool): (bool) Logs the augmented images. (default: True)
def parameters(self) -> None
def backward(self, observation) -> None
def end_batch(self) -> None
module emote.nn.gaussian_policy
Classes
class BasePolicy(nn.Module):
Methods
def __init__(self) -> None
def post_process(self, actions) -> None
Post-process a pre-action into a post-action.
Arguments:
actions
def infer(self, x) -> None
Samples pre-actions and associated post-actions (actual decisions) from the policy given the encoder input.
Only for use at inference time; defaults to identity transformation. Crucial to reimplement for discrete reparametrized policies.
Arguments:
x(Tensor)
class GaussianPolicyHead(nn.Module):
Methods
def __init__(self, hidden_dim, action_dim) -> None
def forward(self, x, epsilon) -> Tensor | Tuple[Tensor]
Sample pre-actions and associated log-probabilities.
Arguments:
x(Tensor)epsilon(Tensor | None)
Returns:
- Direct samples (pre-actions) from the policy log- probabilities associated to those samples
class GaussianMlpPolicy(nn.Module):
Methods
def __init__(self, observation_dim, action_dim, hidden_dims) -> None
def forward(self, obs, epsilon) -> Tensor | Tuple[Tensor]
module emote.nn.initialization
Functions
def ortho_init_(m, gain) -> None
def xavier_uniform_init_(m, gain) -> None
def normal_init_(m) -> None
module emote.nn.layers
Classes
class Conv2dEncoder(nn.Module):
Multi-layer 2D convolutional encoder.
Methods
def __init__(
self,
input_shape,
channels,
kernels,
strides,
padding,
channels_last,
activation,
flatten
) -> None
Arguments:
input_shape(tuple[int, int, int]): (tuple[int, int, int]) The input image shape, this should be consistent with channels_last.channels(list[int]): (list[int]) The number of channels for each conv layer.kernels(list[int]): (list[int]) The kernel size for each conv layer.strides(list[int]): (list[int]) The strides for each conv layer.padding(list[int]): (list[int]]) The padding.channels_last(bool): (bool) Whether the input image has channels as the last dim, else first. (default: True)activation(torch.nn.Module): (torch.nn.Module) The activation function.flatten(bool): (bool) Flattens the output into a vector. (default: True)
def forward(self, obs) -> None
def get_encoder_output_size(self) -> None
class Conv1dEncoder(nn.Module):
Multi-layer 1D convolutional encoder.
Methods
def __init__(
self,
input_shape,
channels,
kernels,
strides,
padding,
activation,
flatten,
name,
channels_last
) -> None
Arguments:
input_shape(tuple[int, int]): (tuple[int, int]) The input shapechannels(list[int]): (list[int]) The number of channels for each conv layer.kernels(list[int]): (list[int]) The kernel size for each conv layer.strides(list[int]): (list[int]) The strides for each conv layer.padding(list[int]): (list[int]) The padding.activation(torch.nn.Module): (torch.nn.Module) The activation function.flatten(bool): (bool) Flattens the output into a vector. (default: True)name(str): (str) Name of the encoder (default: "conv1d") (default: conv1d)channels_last(bool): (bool) Whether the input has channels as the last dim, else first. (default: True)
def forward(self, obs) -> None
def get_encoder_output_size(self) -> None
module emote.optimizers
Functions
def separate_modules_for_weight_decay(
network,
whitelist_weight_modules,
blacklist_weight_modules,
layers_to_exclude
) -> tuple[set[str], set[str]]
Separate the parameters of network into two sets: one set of parameters that will have weight decay, and one set that will not.
Arguments:
network(torch.nn.Module): Network whose modules we want to separate.whitelist_weight_modules(tuple[Type[torch.nn.Module], ...]): Modules that should have weight decay applied to the weights.blacklist_weight_modules(tuple[Type[torch.nn.Module], ...]): Modules that should not have weight decay applied to the weights.layers_to_exclude(set[str] | None): Names of layers that should be excluded. Defaults to None. (default: None)
Returns:
- Sets of modules with and without weight decay.
Classes
class ModifiedAdamW(torch.optim.AdamW):
Modifies AdamW (Adam with weight decay) to not apply weight decay on the bias and layer normalization weights, and optionally additional modules.
Methods
def __init__(
self,
network,
lr,
weight_decay,
whitelist_weight_modules,
blacklist_weight_modules,
layers_to_exclude
) -> None
Arguments:
network(torch.nn.Module): networklr(float): learning rateweight_decay(float): weight decay coefficientwhitelist_weight_modules(tuple[Type[torch.nn.Module], ...]): params to get weight decay. Defaults to (torch.nn.Linear, ). (default: <ast.Attribute object at 0x7ffa75caa200>)blacklist_weight_modules(tuple[Type[torch.nn.Module], ...]): params to not get weight decay. Defaults to (torch.nn.LayerNorm, ). (default: <ast.Attribute object at 0x7ffa75ca9ff0>)layers_to_exclude(set[str] | None): set of names of additional layers to exclude, e.g. last layer of Q-network. Defaults to None. (default: None)
module emote.proxies
Proxies are bridges between the world the agent acts in and the algorithm training loop.
Classes
class AgentProxy(Protocol):
The interface between the agent in the game and the network used during training.
Methods
def __call__(self, obserations) -> Dict[AgentId, DictResponse]
Take observations for the active agents and returns the relevant network output.
Arguments:
obserations(Dict[AgentId, DictObservation])
def policy(self) -> nn.Module
def input_names(self) -> tuple[str, ...]
def output_names(self) -> tuple[str, ...]
class MemoryProxy(Protocol):
The interface between the agent in the game and the memory buffer the network trains from.
Methods
def add(self, observations, responses) -> None
Store episodes in the memory buffer used for training. This is useful e.g. if the data collection is running from a checkpointed model running on another machine.
Arguments:
observations(Dict[AgentId, DictObservation])responses(Dict[AgentId, DictResponse])
class GenericAgentProxy(AgentProxy):
Observations are dicts that contain multiple input and output keys. For example, we might have a policy that takes in both "obs" and "goal" and outputs "actions". In order to be able to properly invoke the network it is the responsibility of this proxy to collate the inputs and decollate the outputs per agent.
Methods
def __init__(
self,
policy,
device,
input_keys,
output_keys,
uses_logprobs,
spaces
) -> None
Handle multi-input multi-output policy networks.
Arguments:
policy(nn.Module): The neural network policy that takes observations and returns actions.device(torch.device): The device to run the policy on.input_keys(tuple): Keys specifying what fields from the observation to pass to the policy.output_keys(tuple): Keys for the fields in the output dictionary that the policy is responsible for.uses_logprobs(bool)(default: True)spaces(MDPSpace | None): A utility for managing observation and action spaces, for validation.
def __call__(self, observations) -> dict[AgentId, DictResponse]
Runs the policy and returns the actions.
Arguments:
observations(dict[AgentId, DictObservation])
def input_names(self) -> None
def output_names(self) -> None
def policy(self) -> None
module emote.trainer
Classes
class StateDict(dict, MutableMapping[str, Any]):
Wrapped around a dict allowing usage in a weakref.
Methods
def get_handle(self) -> WeakReference['StateDict']
Retrieve a weak handle to this state dict, with no promise of ownership or lifetime.
class TrainingShutdownException(Exception):
class Trainer:
The Trainer class manages the main training loop in emote. It does so by invoking a bunch of callbacks in a number of different places.
Fields
-
state:StateDict -
callbacks:List[Callback] -
dataloader:Iterable -
cycle_length:int
Methods
def __init__(self, callbacks, dataloader, batch_size_key) -> None
Arguments:
callbacks(List[Callback])dataloader(Iterable)batch_size_key(str)(default: batch_size)
def train(self, shutdown_signal) -> None
The main training loop. This method will wait until the memory is full enough to start sampling, and then start running cycles of backprops on batches sampled from the memory.
Arguments:
shutdown_signal(Callable): A function that returns True if training shut end, False otherwise.
module emote.typing
emote.typing
Type Aliases
type RewardFnType: Callable[[torch.Tensor, torch.Tensor], torch.Tensor]
Classes
class EpisodeState(Enum):
class MetaData:
Fields
-
info:Dict[str, float] -
info_lists:Dict[str, FloatList]
class DictObservation:
Fields
-
rewards:Dict[str, float] -
episode_state:EpisodeState -
array_data:Dict[str, SingleAgentData] -
metadata:MetaData=None
class DictResponse:
Fields
-
list_data:Dict[str, FloatList] -
scalar_data:Dict[str, float]
package emote.utils
Classes
class WeakReference(ReferenceType, Generic[T]):
A typed weak reference.
class LockedResource(Generic[T]):
Context manager for a lock and a resource.
Only giving access to the
resource when locked. Works well when paired with [empyc.types.Ref]
for primitive types as well.
Usage:
resource = LockedResource([])
with resource as inner_list:
inner_list.append(1)
Methods
def __init__(self, data) -> None
Create a new LockedResource, with the provided data.
Arguments:
data(T): The data to lock
def swap(self, new_resource) -> T
Replace the contained resource with the provided new resource, returning the previous resource. This operation is atomic.
Arguments:
new_resource(T): The resource to lock after the swap
Returns:
- The previously guarded data
class AtomicContainer:
Container that allows atomic set, get, take operations.
Methods
def __init__(self, initial_data) -> None
Arguments:
initial_data(Any)
def take(self) -> Any
def read(self) -> Any
def set(self, value) -> None
class AtomicInt:
Methods
def __init__(self, value) -> None
def swap(self, value) -> None
def increment(self, value) -> None
Increments the integer and returns the previous value.
Arguments:
value(int)(default: 1)
class TimedBlock:
Used to track the performance statistics of a block of code, in terms of execution time.
Methods
def __init__(self, tracker_type) -> None
Create a new timed block instance.
Arguments:
tracker_type(Type[StatisticsAccumulator]): The statistics integrator to use. Defaults to to MovingWindowStats
def mean(self) -> float
Retrieve the mean execution time.
def var(self) -> None
Retrieve the variance of the execution time.
def stats(self) -> None
Retrieve the mean and the variance of execution time.
class BlockTimers:
Methods
def __init__(self, tracker_type) -> None
def scope(self, name) -> TimedBlock
def stats(self) -> None
class MDPSpace:
Fields
-
rewards:BoxSpace -
actions:BoxSpace -
state:DictSpace
module emote.utils.deprecated
Functions
def deprecated(original_function, *reason, max_warn_count, version) -> Callable
Function decorator to deprecate an annotated function. Can be used both as a bare decorator, or with parameters to customize the display of the message. Writes to logging.warn.
Arguments:
original_function(Callable): Function to decorate. Automatically passed.reason(str): Message to show. Function name is automatically added.max_warn_count(int): How many times we will warn for the same functionversion(str)
Returns:
- the wrapped function
module emote.utils.gamma_matrix
Functions
def make_gamma_matrix(gamma, roll_length) -> None
def discount(rewards, values, gamma_matrix) -> None
def split_rollouts(data, rollout_len) -> None
module emote.utils.math
Functions
def truncated_linear(min_x, max_x, min_y, max_y, x) -> float
Truncated linear function. Implements the following function:
\[ \begin{cases} f1(x) = \frac{min_y + (x - min_x)}{ (max_x - min_x) * (max_y - min_y)} \\ f(x) = min(max_y, max(min_y, f1(x))) \end{cases} \] If max_x - min_x < 1e-10, then it behaves as the constant \(f(x) = max_y\)
Arguments:
min_x(float)max_x(float)min_y(float)max_y(float)x(float)
def truncated_normal_(tensor, mean, std) -> torch.Tensor
Samples from a truncated normal distribution in-place.
Arguments:
tensor(torch.Tensor): the tensor in which sampled values will be stored.mean(float): the desired mean (default = 0).std(float): the desired standard deviation (default = 1). (default: 1)
Returns:
- the tensor with the stored values. Note that this modifies the input tensor in place, so this is just a pointer to the same object.
module emote.utils.model
Functions
def to_numpy(x) -> None
def normal_init(m) -> None
module emote.utils.spaces
Classes
class BoxSpace:
Fields
-
dtype:torch.dtype | np.dtype -
shape:Tuple[int]
class DictSpace:
Fields
spaces:Dict[str, BoxSpace]
class MDPSpace:
Fields
-
rewards:BoxSpace -
actions:BoxSpace -
state:DictSpace
module emote.utils.threading
Thread-related utilities and tools.
Classes
class LockedResource(Generic[T]):
Context manager for a lock and a resource.
Only giving access to the
resource when locked. Works well when paired with [empyc.types.Ref]
for primitive types as well.
Usage:
resource = LockedResource([])
with resource as inner_list:
inner_list.append(1)
Methods
def __init__(self, data) -> None
Create a new LockedResource, with the provided data.
Arguments:
data(T): The data to lock
def swap(self, new_resource) -> T
Replace the contained resource with the provided new resource, returning the previous resource. This operation is atomic.
Arguments:
new_resource(T): The resource to lock after the swap
Returns:
- The previously guarded data
class AtomicContainer:
Container that allows atomic set, get, take operations.
Methods
def __init__(self, initial_data) -> None
Arguments:
initial_data(Any)
def take(self) -> Any
def read(self) -> Any
def set(self, value) -> None
class AtomicInt:
Methods
def __init__(self, value) -> None
def swap(self, value) -> None
def increment(self, value) -> None
Increments the integer and returns the previous value.
Arguments:
value(int)(default: 1)
class TracedLock:
module emote.utils.timed_call
Simple block-based timers using Welford's Online Algorithm to approximate mean and variance.
Usage:
timer = TimedBlock()
for _ in range(10):
with timer():
sleep(1)
print(time.sleep())
# (1.000013, 1.3e-5)
## Classes
### `class StatisticsAccumulator(ABC):`
<div style="padding-left: 20px;">
Interface for a statistics integrator.
#### Methods
```python
def add(self, value) -> None
Add the value to the running statistics.
Arguments:
value(float): the sample to integrate
def current(self) -> Tuple[float, float]
Returns the statistics of the observed samples so far.
Returns:
- a tuple (mean, variance)